

Representative verbal skill fragment extraction device and method based on seat voice segmentation
A voice segment and voice segmentation technology, applied in the field of speech recognition, can solve the problems of time-consuming and labor-intensive learning, agents spend a lot of time, and it is difficult to be used as a reference for agents to improve the quality of their own speech, so as to improve the reference value. , the effect of saving time for self-improvement and learning
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0022] In order to make the technical means, creative features, goals and effects achieved by the present invention easy to understand, the device and method for extracting representative speech segments based on agent voice segmentation of the present invention will be described in detail below in conjunction with the embodiments and accompanying drawings.
[0023]
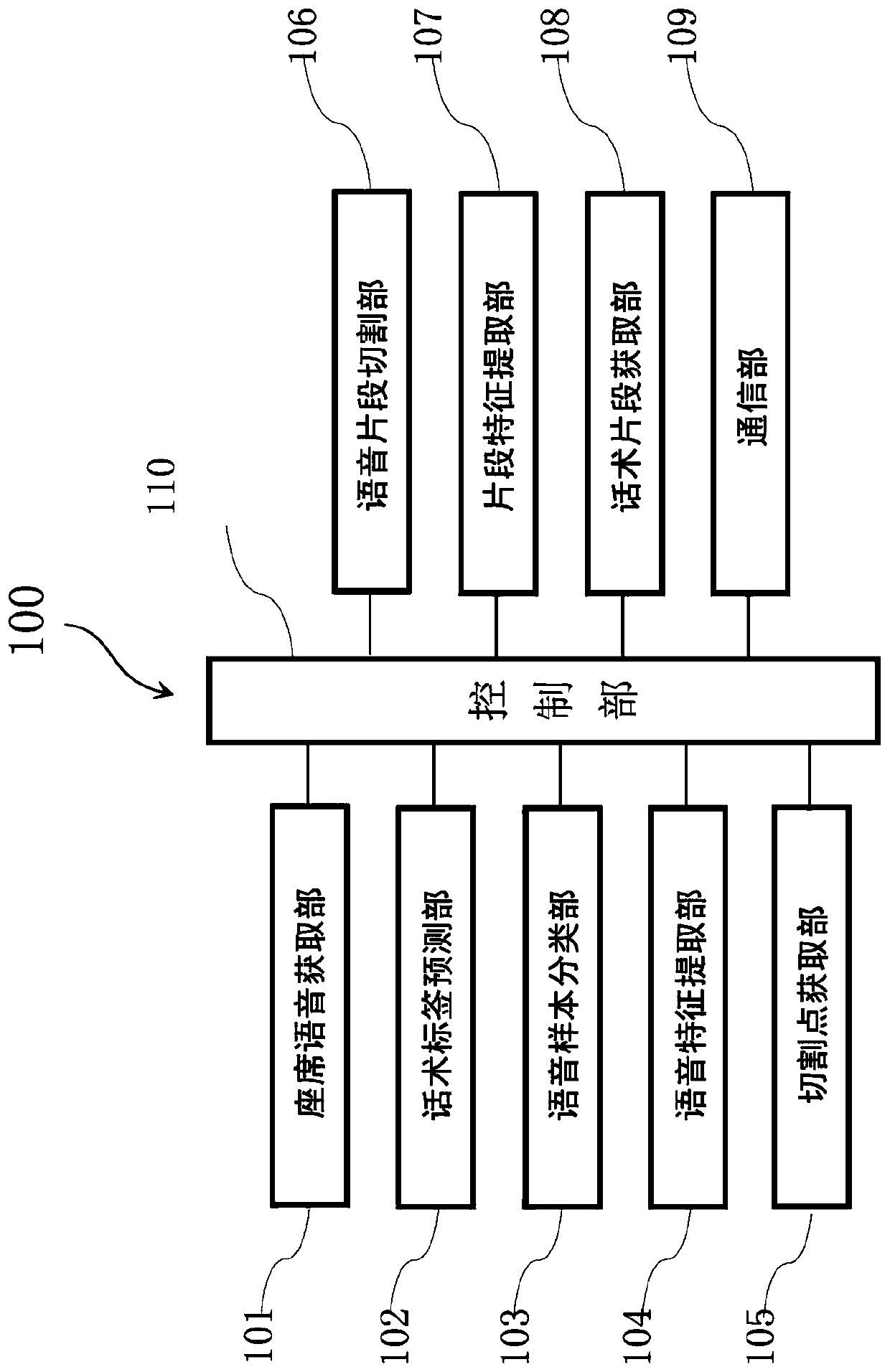
[0024] figure 1 It is a structural block diagram of a representative speech segment extraction device based on agent speech segmentation in an embodiment of the present invention.
[0025] Such as figure 1 As shown, the representative speech segment extraction device 100 based on agent speech segmentation has an agent speech acquisition unit 101, a speech label prediction unit 102, a speech sample classification unit 103, a speech feature extraction unit 104, a cutting point acquisition unit 105, a speech A segment cutting unit 106 , a segment feature extraction unit 107 , a speech segment acquisition unit 108...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More