

Grammar error correction model training method and device and grammar error correction method and device
An error correction model and training method technology, applied in the computer field, can solve problems such as unreachable, lack of labeled data, time-consuming and labor-intensive manual labeling data, etc., to achieve the effect of expanding data, increasing accuracy, and reducing manual labor
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
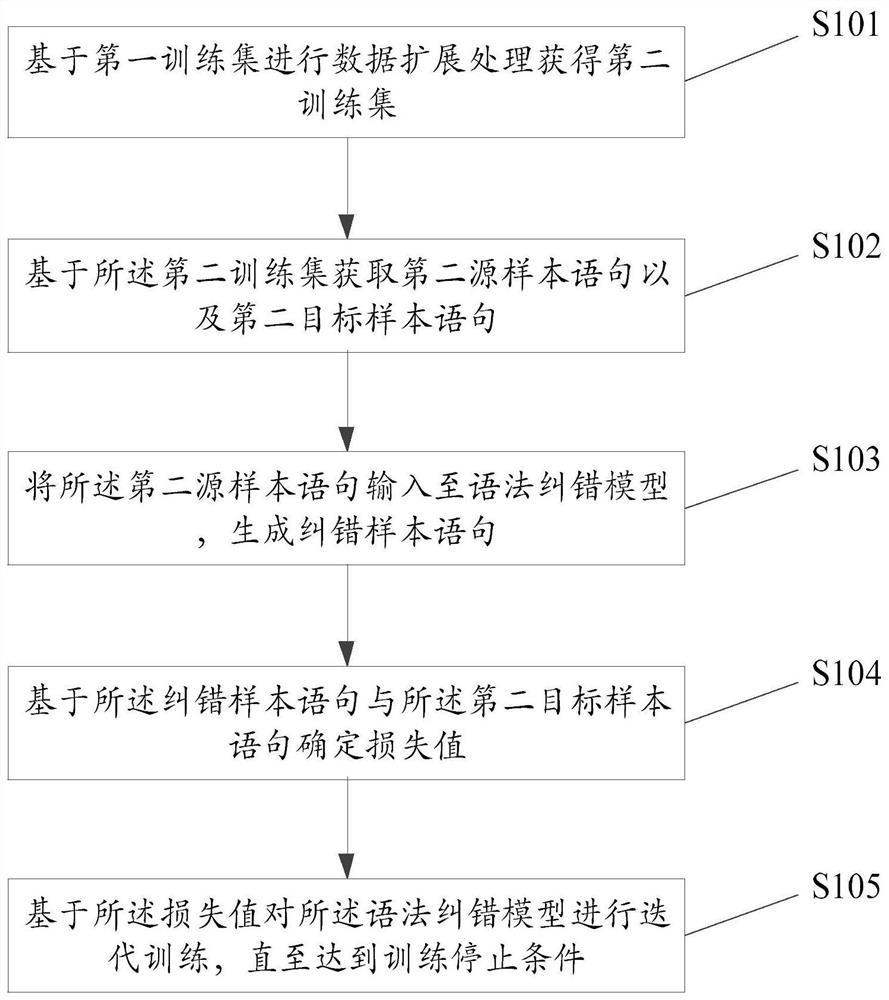
[0103] This embodiment provides a training method for an error correction model, see figure 1 As shown, the training method includes steps S101 to S105, and each step will be described in detail below.
[0104] S101. Perform data expansion processing based on the first training set to obtain a second training set.
[0105] In this embodiment, the first training set is an existing training set with less data. It is divided into source end (source statement end) and target end (target statement end). In the first training set, the source end (source sentence end) includes the first source sample sentence, and the target end (target sentence end) includes the first target sample sentence. The first source sample sentence is a sentence with grammatical errors, and the first target sample sentence is a grammatically correct target sample sentence corresponding to the first source sample sentence.
[0106] For example, in the first training set, the first source sample sentence i...
Embodiment 2
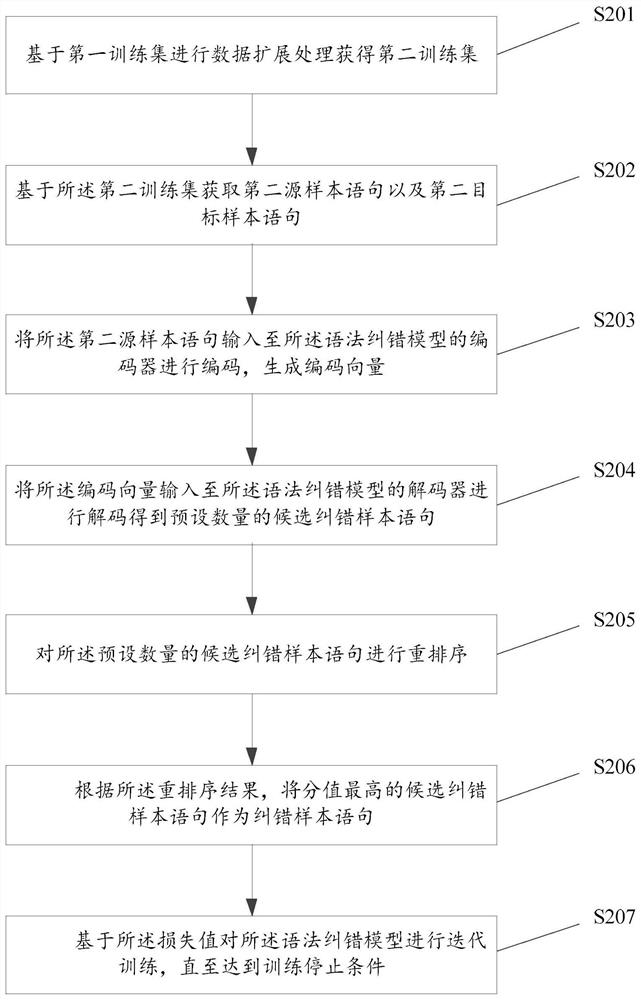
[0134] This embodiment provides a training method for a grammatical error correction model, see figure 2 As shown, steps S201 to S207 are specifically included.
[0135] S201. Perform data expansion processing based on the first training set to obtain a second training set.
[0136] In this embodiment, the first training set includes a first source sample sentence and a first target sample sentence.
[0137] The first training set is an existing training set with less data. It is divided into source end (source statement end) and target end (target statement end). In the first training set, the source end (source sentence end) includes the first source sample sentence, and the target end (target sentence end) includes the first target sample sentence. The first source sample sentence is a sentence with grammatical errors, and the first target sample sentence is a grammatically correct target sample sentence corresponding to the first source sample sentence.
[0138] Speci...
Embodiment 3
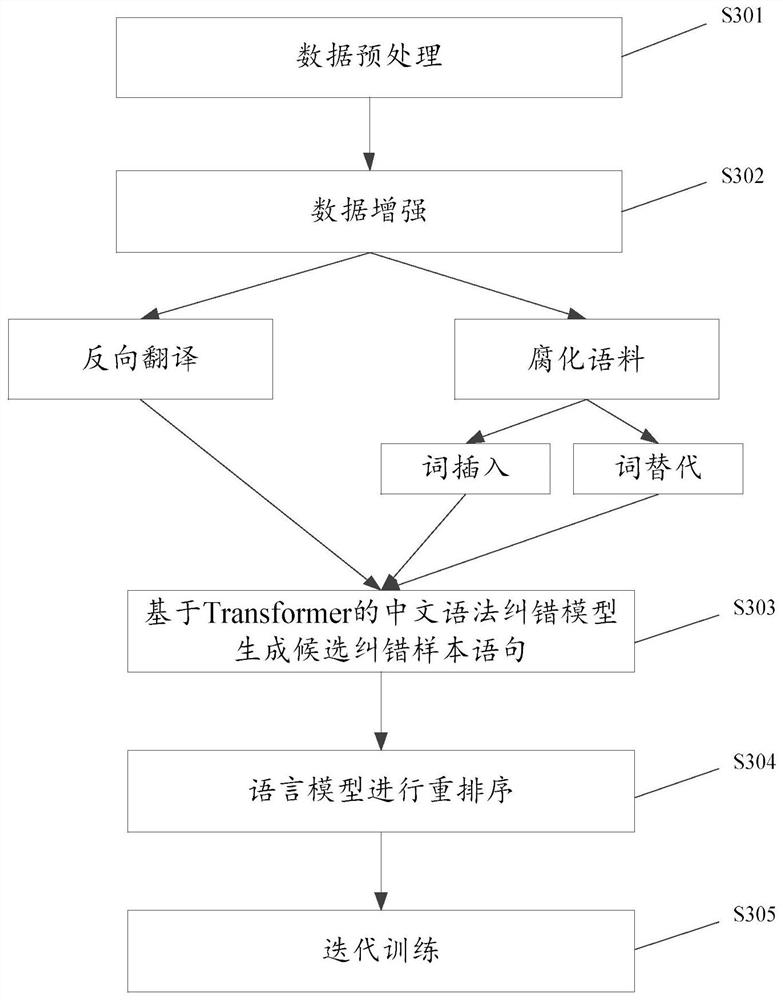
[0230] This embodiment provides a grammatical error correction model training method, see image 3 shown, including the following steps:
[0231] S301. Data preprocessing.
[0232] Specifically, preprocessing the first source sample sentence and the first target sample sentence in the existing first training set includes:
[0233] performing word segmentation processing on the first source sample sentence and the first target sample sentence, and separating each word unit;
[0234] removing sentences whose sentence length is greater than a preset threshold in the first training set;
[0235] The same sentences in the first source sample sentence and the first target sample sentence are removed.
[0236] Further, each word unit in all sentences included in the first source sample sentence and the first target sample sentence is separated from each other by spaces; then the first training set is too long or too short Delete, for example word unit is too long sentence more th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More