

Pre-trained language model quantification method and device
A language model and quantification method technology, applied in neural learning methods, biological neural network models, natural language data processing, etc., can solve the problems of low model accuracy, poor compression effect, and much decline in quantitative model performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment approach
[0133] As an implementation, the above-mentioned electronic equipment is applied to a pre-trained language model quantization device, including:
[0134] at least one processor; and a memory communicatively connected to the at least one processor; wherein the memory stores instructions executable by the at least one processor, the instructions are executed by the at least one processor so that the at least one processor can:
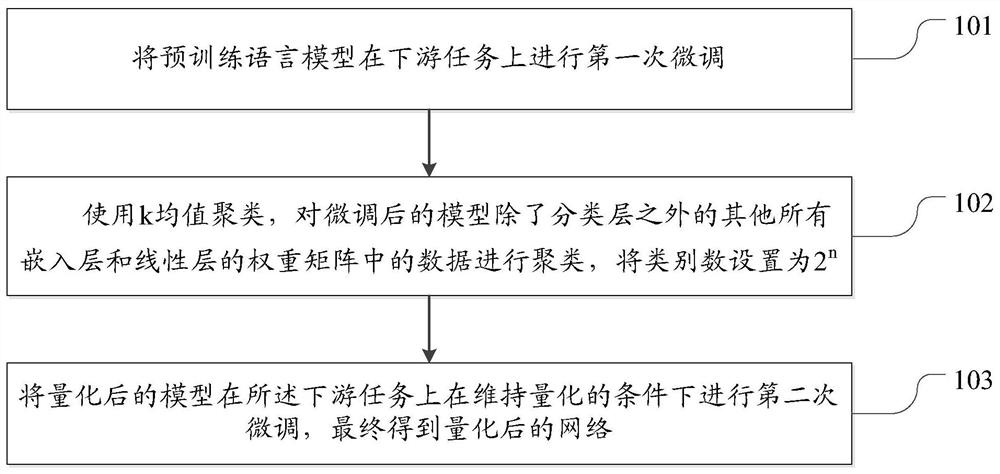
[0135] Perform the first fine-tuning of the pre-trained language model on downstream tasks;
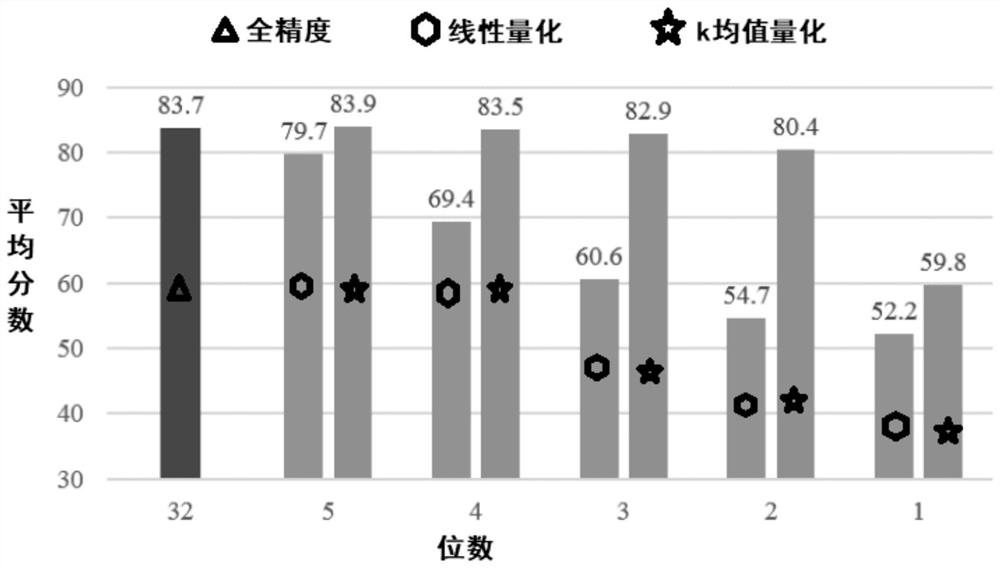
[0136] Using k-means clustering, cluster the data in the weight matrices of all embedding layers and all linear layers of the fine-tuned model except the classification layer, and set the number of categories to 2 n , where n is the number of bits occupied by each data of the compressed target model;
[0137] The quantized model is fine-tuned for the second time on the downstream task under the condition of maintaining the quantization, and finally the quantize...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More