

Text semantic analysis and feature value extraction method
A semantic analysis and extraction method technology, applied in the field of automatic text information processing, can solve the problems of low efficiency and inability to continue to improve the text similarity judgment, and achieve the effect of improving classification accuracy, improving performance and optimizing performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0041] The invention provides a method for text semantic analysis and feature value extraction, which specifically includes the following steps:
[0042] Step 10: Text extraction, using a text extraction tool to extract text from the target document;
[0043] Step 20: preprocessing, after obtaining the initial text in step 10, judge and process typos and typos, and obtain a preprocessing text with correct content;
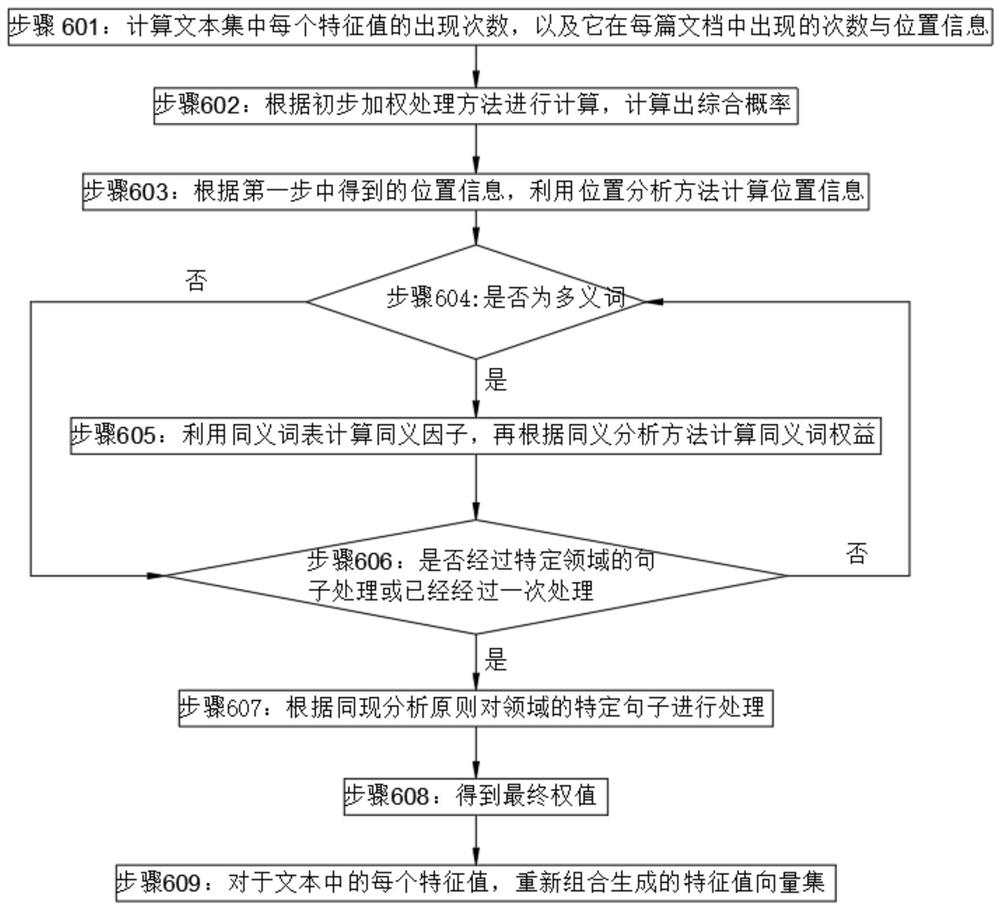
[0044] Step 30: Construct a text corpus, construct a text corpus with words as the smallest unit, extract attributes, perform semantic weight calculations, and obtain word meaning weights, and based on this, perform association weight calculations to obtain association weights of associated words;
[0045] Step 40: Synonym analysis, map the original feature words as the basic unit of text feature extraction to synonymous concepts as the unit of feature extraction, and use the weight of each synonymous concept class obtained from the text corpus to find the correspo...
Embodiment 2
[0061] The invention provides a method for text semantic analysis and feature value extraction, which specifically includes the following steps:
[0062] Step 10: Text extraction, using a text extraction tool to extract text from the target document;
[0063] Step 20: preprocessing, after obtaining the initial text in step 10, judge and process typos and typos, and obtain a preprocessing text with correct content;
[0064] Step 30: Construct a text corpus, construct a text corpus with words as the smallest unit, extract attributes, perform semantic weight calculations, and obtain word meaning weights, and based on this, perform association weight calculations to obtain association weights of associated words;
[0065] Step 40: Synonym analysis, map the original feature words as the basic unit of text feature extraction to synonymous concepts as the unit of feature extraction, and use the weight of each synonymous concept class obtained from the text corpus to find the correspo...
Embodiment 3
[0081] The invention provides a method for text semantic analysis and feature value extraction, which specifically includes the following steps:
[0082] Step 10: Text extraction, using a text extraction tool to extract text from the target document;
[0083] Step 20: preprocessing, after obtaining the initial text in step 10, judge and process typos and typos, and obtain a preprocessing text with correct content;
[0084] Step 30: Construct a text corpus, construct a text corpus with words as the smallest unit, extract attributes, perform semantic weight calculations, and obtain word meaning weights, and based on this, perform association weight calculations to obtain association weights of associated words;
[0085] Step 40: Synonym analysis, map the original feature words as the basic unit of text feature extraction to synonymous concepts as the unit of feature extraction, and use the weight of each synonymous concept class obtained from the text corpus to find the correspo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More