

Cross-modal video retrieval method and system based on multi-head self-attention mechanism and storage medium
An attention, cross-modal technology, applied in the video field, can solve the problem of maintaining semantic similarity of data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

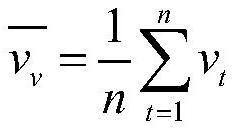
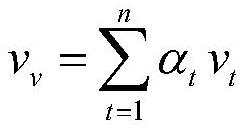
Examples
Embodiment Construction
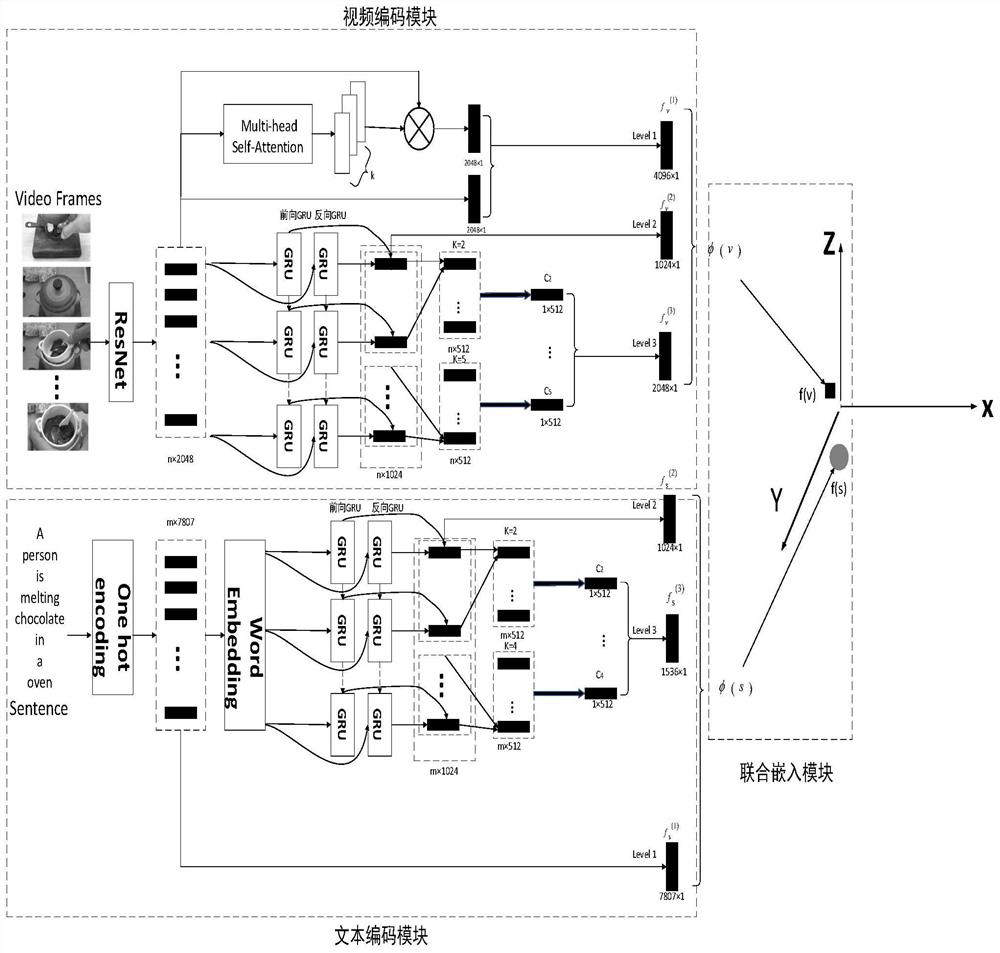
[0032] The invention discloses a cross-modal video retrieval method based on a multi-head self-attention mechanism. The invention mainly aims at the problem of how to fully mine the semantic information inside multi-modal data and generate efficient vectors. Through the form of supervised training, make full use of the semantic information in training multi-modal data for training, and introduce a multi-head self-attention mechanism to capture the subtle interactions within videos and texts, and selectively focus on the key points of multi-modal data Information is used to enhance the representation ability of the model, better mine data semantics, and ensure the consistency of data distances in the original space and in the shared subspace. When training the model, a supervised machine learning method is used, and a triple-based sorting loss function is used to introduce the order of positive samples in each batch, which better corrects the sorting error. For two different mo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More