Heterogeneous legal data-oriented multi-task reading system and method
A reading system and multi-task technology, applied in the field of multi-task reading systems for heterogeneous legal data, can solve problems such as unanswerable questions, inferences to give answers, and inability to give answers to preset questions, etc. The effect of solving the heterogeneity problem
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
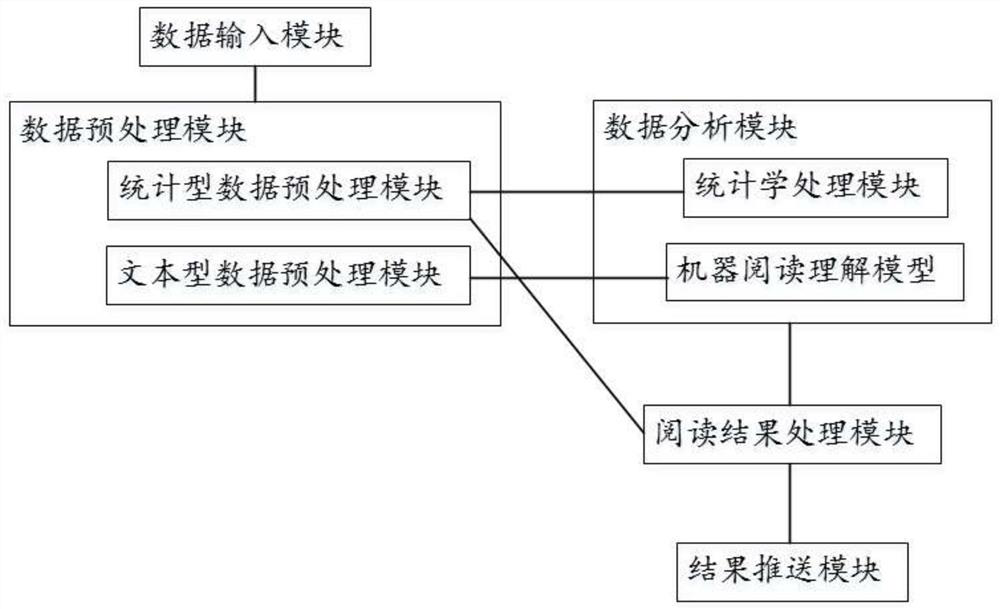
[0040] Such as figure 1 As shown, this embodiment provides a multi-task reading system for heterogeneous legal data, which includes sequentially connected:
[0041] Data input module for inputting statistical and textual legal data;
[0042] Data preprocessing module, used for data cleaning and data conversion of legal data;
[0043] The data analysis module is used to analyze the preprocessed data;
[0044] The reading result processing module is used to integrate the analyzed data to form structured reading result data;
[0045] The result push module is used to feed back the reading result data to legal researchers.
[0046] In this embodiment, the data preprocessing module includes a statistical data preprocessing module and a text data preprocessing module, and the statistical data preprocessing module is used to fill missing items in the statistical data, delete or replace abnormal items, The outlier data is counted, and the text data preprocessing module is used to ...
Embodiment 2
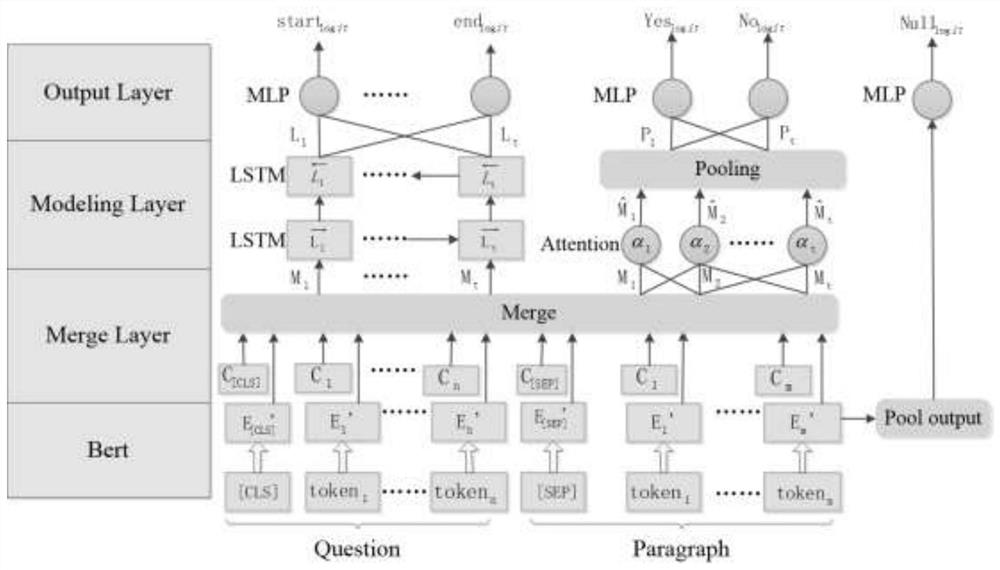
[0112] In this embodiment, two benchmarks are set: BIDAF and Bert, which are tested together with the model LegalSelfReader proposed in this embodiment.
[0113] lab environment
[0114] Experiment on a machine with 64-bit Windows system. The external storage space of the machine is 930GB, the memory space is 48GB, the CPU type is single-core Intel i7-8700K, the GPU type is NVIDA GeForceGTX 1080Ti, and the GPU size is 11GB. All experimental programs in this embodiment are written in python language, and the deep learning framework used is Pytorch, version number is 1.13.0.
[0115] The original data used in this example comes from the CAIL 2019 Legal Reading Comprehension Competition 1. This dataset is released by the Xunfei Joint Laboratory of Harbin Institute of Technology and University of Science and Technology. It is a multi-task machine reading comprehension dataset for the judicial field. The dataset name is CJRC. The chapters of the data set come from the China Judgm...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More