AI technical title is built by Patsnap AI team. It summarizes the technical point description of the patent document.
An emotion recognition, multi-modal technology, applied in the field of data processing, can solve the problems of long sequence context modeling and other problems, achieve the effect of limited ability to solve and improve accuracy
Active Publication Date: 2021-03-26
INST OF AUTOMATION CHINESE ACAD OF SCI
View PDF3 Cites 16 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
In addition, in addition to multimodal fusion, in terms of model architecture, current multimodal emotion recognition methods mainly use recurrent neural networks to capture temporal context information. Stretched
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
Embodiment 1
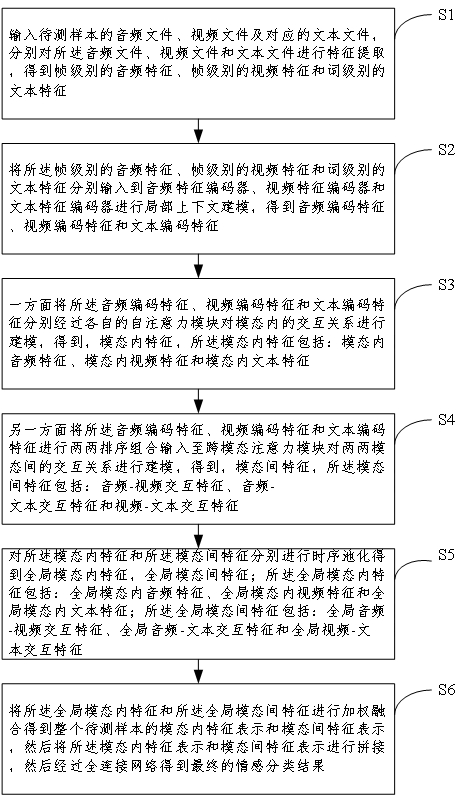
[0059] Such as figure 1 As shown, the multimodal emotion recognition method provided by the embodiment of the present application includes:
[0060] S1: Input the audio file, video file and corresponding text file of the sample to be tested, perform feature extraction on the audio file, video file and text file respectively, and obtain the audio feature at the frame level, the video feature at the frame level and the word level text features.
[0061] In some embodiments, the specific method for feature extraction of the audio file, video file and text file respectively includes:
[0062] Segmenting the audio file to obtain frame-level short-term audio clips; respectively inputting the short-time audio clips to a pre-trained audio feature extraction network to obtain the frame-level audio features;
[0063] Utilize face detection tool to extract the human face image of frame level from described video file; Input the human face image of described frame level into pre-trained...
Embodiment 2
[0110] The present application also discloses an electronic device, including a memory, a processor, and a computer program stored on the memory and operable on the processor. When the processor executes the computer program, the methods described in the above-mentioned embodiments are implemented. A step of.
Embodiment 3
[0112] The multimodal emotion recognition method includes the following steps:
[0113] S1-1: Input the audio to be tested, the video to be tested, and the text to be tested. The video and audio to be tested, the video to be tested, and the text to be tested are three different modalities.
[0114] In this embodiment, the audio to be tested and the video to be tested are video and audio in the same segment, the text to be tested corresponds to the audio to be tested and the video to be tested, and audio, video, and text are three types of video in this video modal.
[0115] In this embodiment, the data of these three modalities need to be analyzed in this embodiment to detect the emotional state of the character in the input segment.
[0116] According to the above scheme, further, a segment can be input, in which a character speaks, the continuous picture of this character speaking is the video to be tested, the audio that appears in the segment is the audio to be tested, th...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention relates to a multi-modalemotion recognition method. The method comprises the steps of extracting frame-level audio features, frame-level video features and word-level text features respectively; respectively inputting the extracted features into a feature encoder for modeling to obtain encoded audio encoding, video encoding and text encoding features; modeling an interaction relationship in a modal by using coded features through respective self-attention modules, sorting and combining the interaction relationships in pairs, and inputting the sorted and combined interaction relationships into a cross-modal attention module to model the interaction relationship between every two modals; performing time sequencepooling on output of the self-attention module and the cross-modal attention module to obtain global interaction features in all modals and global interaction features between every two modals; and respectively carrying out weighted fusion on the global interactioncharacteristics in the modals and between the modals by utilizing an attention mechanism to obtain characteristic representations in the modals and between the modals of the whole sample to be detected, and splicing the two to be detected to obtain a final emotion classification result through a full connection network.
Description
technical field [0001] The present application relates to the field of data processing, in particular to a multi-modal emotion recognition method. Background technique [0002] Traditional emotion recognition is often limited to a single modality, such as speech emotion recognition, facial expression recognition, and text emotion analysis. With the development of computer science and technology, multi-modal emotion recognition methods based on audio, video and text have emerged, and will be widely used in smart home, education, and finance in the future. Existing multi-modal emotion recognition methods usually use feature-level fusion or decision-level fusion to integrate information from multiple modalities. These methods have their own advantages and disadvantages. Although the feature layer fusion can model the interaction between modalities, it needs to align the features of different modalities in advance in time sequence. The decision-making layer fusion is the oppos...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



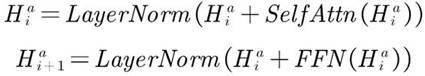
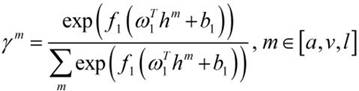
 Login to View More
Login to View More  Login to View More
Login to View More