

Speaker recognition method and device and electronic equipment
A speaker recognition and speaker technology, applied in the field of speaker recognition method, video processing method, device and electronic equipment, can solve the problems of wrong speech segment, wrong speech segment, wrong speaker identification, etc. The effect of accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
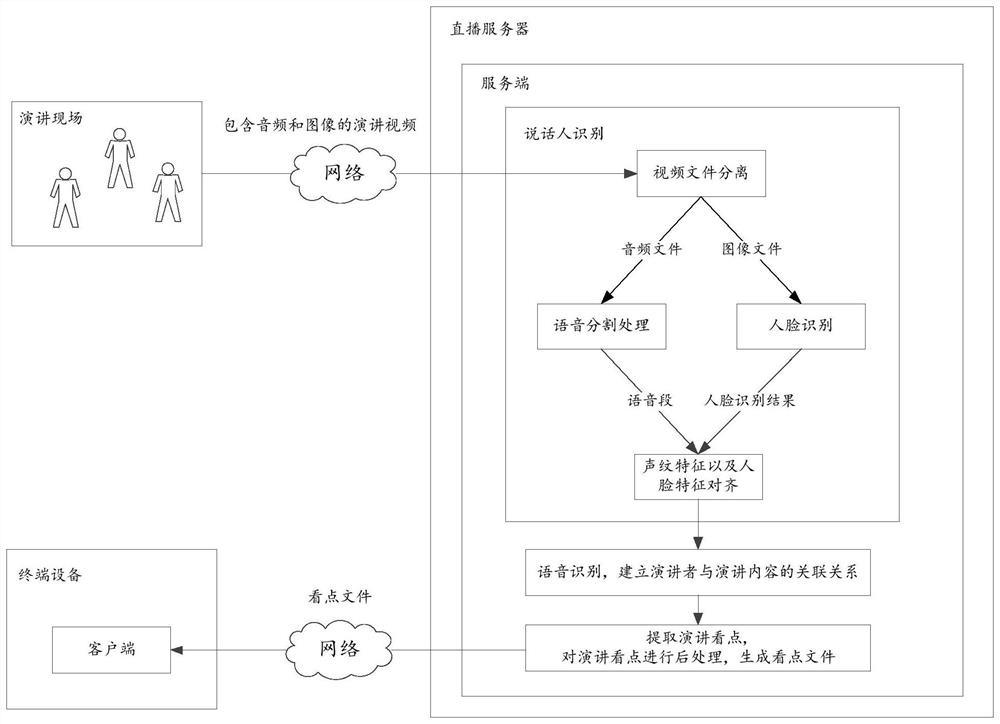
[0071] In order to solve the problem of low speaker recognition accuracy under the influence of environmental noise and other factors in a multi-person speaking scenario, an embodiment of the present application provides a tool for speaker recognition based on voiceprint features and face features. The identification process is explained below with reference to specific examples.
[0072] The identification objects involved in the embodiments of the present application are mainly video files including audio and images. After the video file to be recognized is obtained, the sound and image can be separated first, and the video file can be split into an audio file that can extract voiceprint features and an image file that can extract face features. For example, the audio file and the image file can be separated from the video file by the multimedia video processing tool FFmpeg (FastForward Mpeg).
[0073] For audio files, voiceprint tracking technology can be used for voice se...
Embodiment 2
[0104] For the live broadcast of the speech, the existing technology can only extract the speech points of different speakers through manual analysis after the end of the live broadcast, and then manually add it to the video file, resulting in a lot of labor cost and time cost in the video processing process. .
[0105] Corresponding to this, this embodiment provides a tool that can automatically process video files, such as figure 1 As shown, it can include a client and a server. The client can be deployed on a terminal device associated with the user, and the server can be deployed on a cloud server, for example, a live broadcast server, and the speaker recognition tool provided in Embodiment 1 can be used as a function of the server. Speaker identity in speech videos and determine the set of speech segments associated with different speakers.
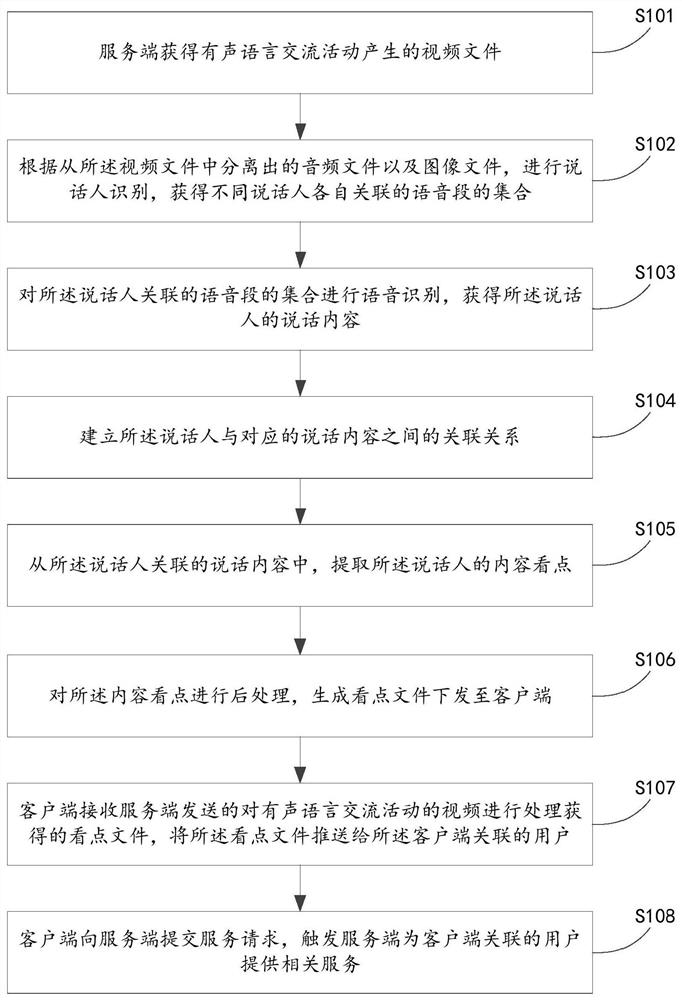
[0106] Combine below figure 2 The flow chart shown is to explain the processing procedure of the video file.
[0107] S101: Th...
Embodiment 3
[0169] This embodiment 3 is corresponding to embodiment 1, provides a kind of speaker recognition method, see Figure 5 , the method may specifically include:
[0170] S201: Separate and obtain an audio file and an image file from the video file to be identified;
[0171] S202: Perform voice segmentation on the audio file, obtain start and end time information and speaker identification information corresponding to at least one voice segment, and perform face recognition on the image file to obtain face recognition results corresponding to different times;
[0172] S203: Perform temporal alignment processing on the speaker identification information and the face recognition result to determine a speaker corresponding to the at least one speech segment.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More