

Tibetan Weizang dialect spoken language recognition method based on deep time delay neural network
A neural network and spoken language recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of large differences in pronunciation characteristics and need to be improved, so as to increase diversity, increase recognition accuracy and generalization performance, and improve recognition. effect of effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach
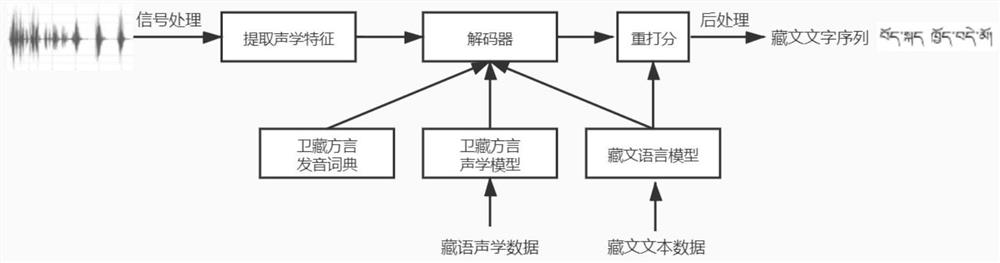
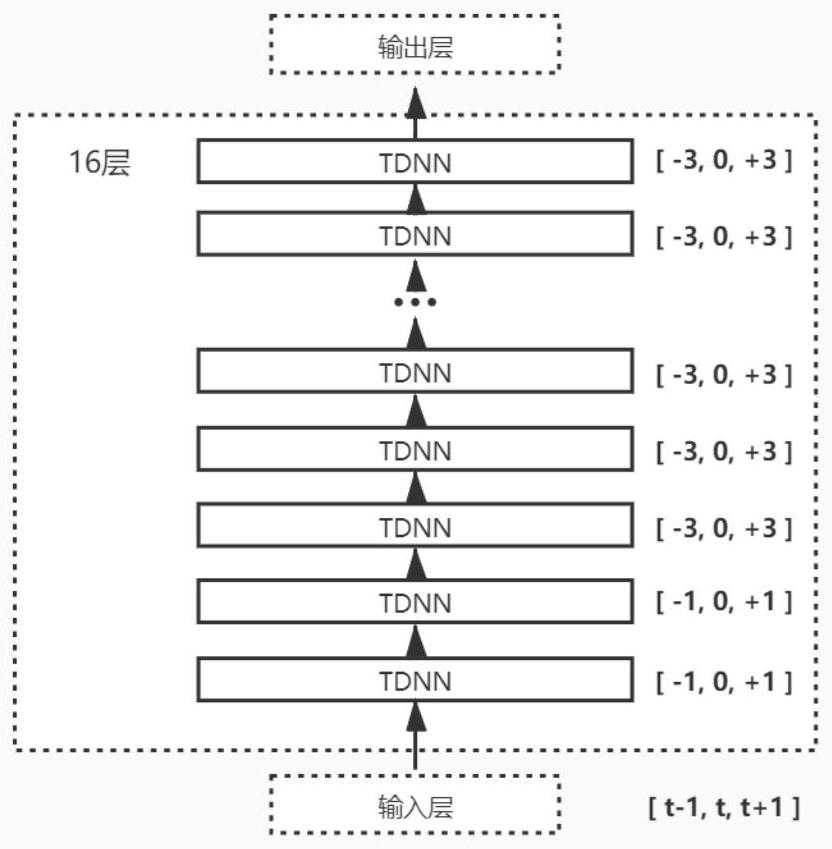
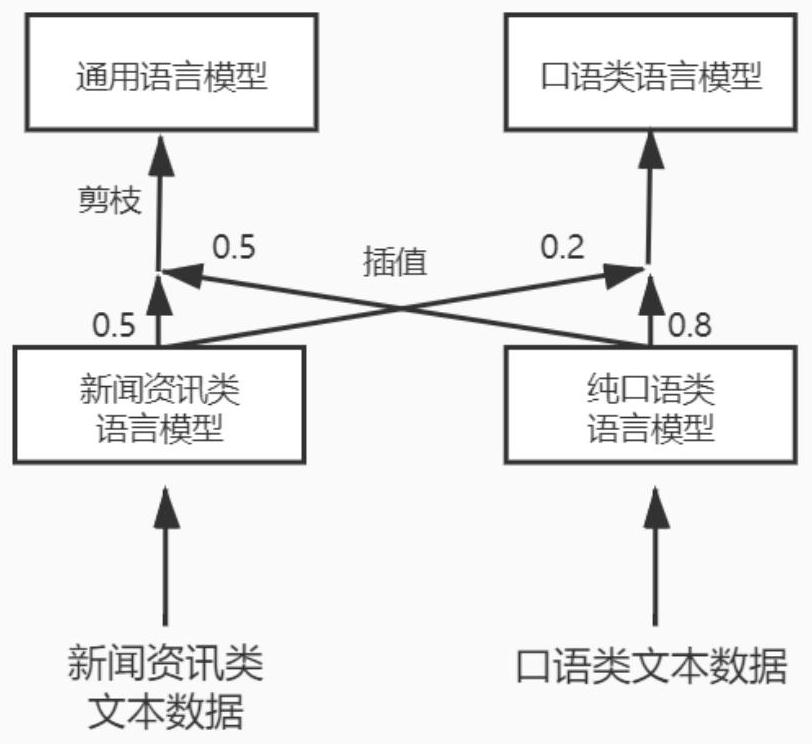
[0057] The present invention is a technical scheme of a Tibetan U-Tibetan dialect spoken language recognition model based on a deep time-delay neural network. The construction work is mainly based on the Linux system experimental environment and the kaldi speech recognition toolbox, and some steps need to use GPU to speed up the operation. The specific implementation method comprises the following steps:
[0058] Step one, prepare the Tibetan audio dataset and then augment it with augmentation techniques. Its operation process is mainly divided into the following aspects:
[0059] First, prepare the acoustic training data. The Tibetan audio data set used when carrying out the model training experiment in the present invention is divided into two parts: a part is the small-scale audio data set of Tibetan U-Tibet dialect, about 36 hours long; The audio data sets of the three Tibetan dialects, Amdo dialect and Amdo dialect, are about 200 hours long. Due to the small size of th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More