

System for modeling 3D scene from single design picture
A picture modeling and 3D technology, applied in the field of computer vision, can solve problems such as wasting time, achieve the effect of reducing construction time and speeding up construction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
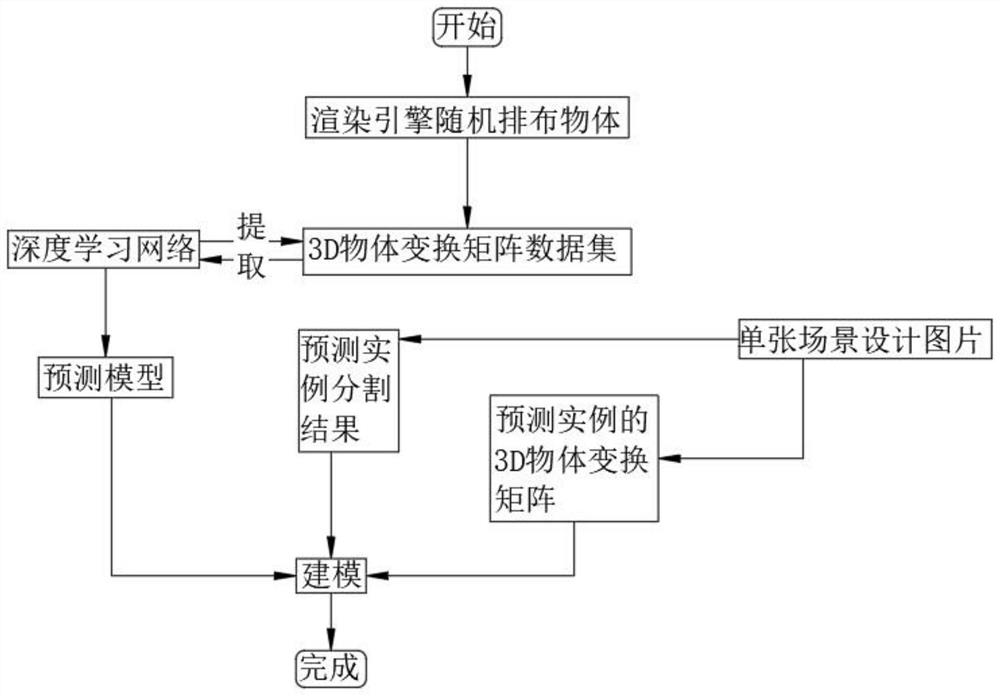
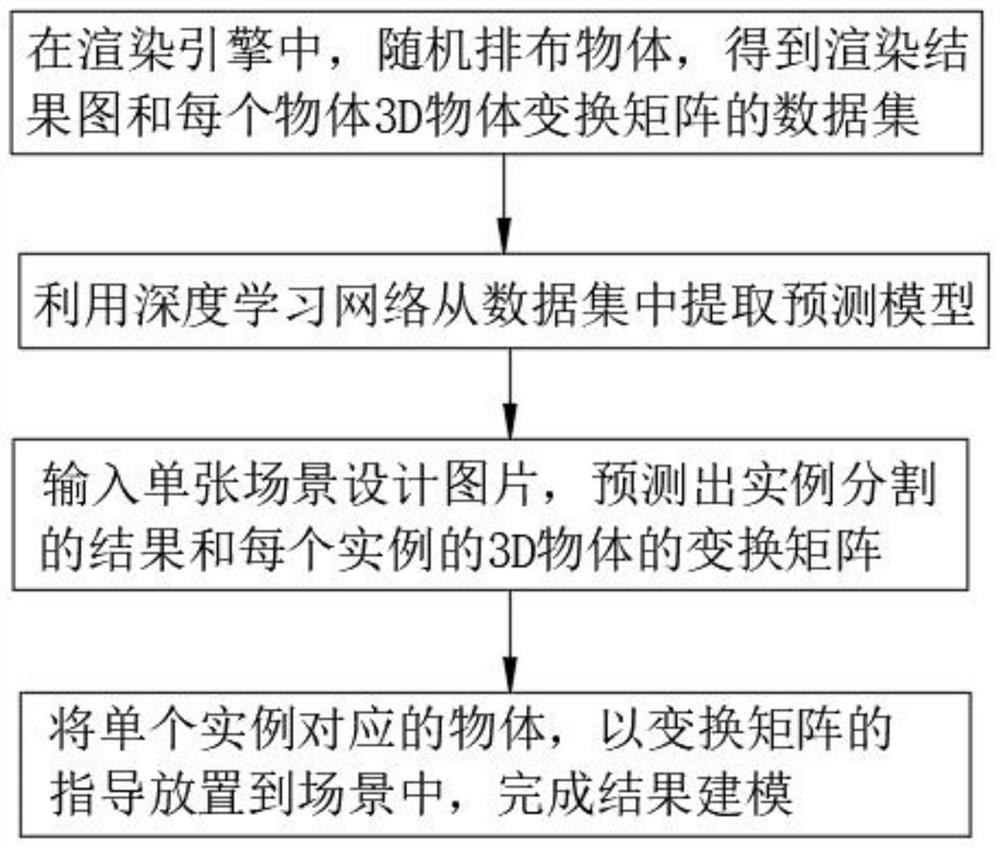
[0047] The present invention provides a 3D scene modeling system from a single design picture, please refer to Figure 1-Figure 3 , including the following steps:
[0048] Rendering: In the rendering engine, objects are randomly arranged to obtain the rendering result graph and the data set of the 3D object transformation matrix of each object;
[0049] Extracting models: using deep learning networks to extract predictive models from datasets;
[0050] Instance segmentation: Input a single scene design picture, predict the result of instance segmentation and the transformation matrix of the 3D object of each instance;
[0051] Modeling: Place the object corresponding to a single instance into the scene under the guidance of the transformation matrix to complete the resulting modeling.
[0052] Further, the data set adopts the InGame loading material method, and the method steps are as follows:
[0053] Randomly load models from the model library and place them;
[0054] Re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More