Parallel method and device for convolution calculation and data loading of neural network accelerator
A neural network and accelerator technology, applied in the field of neural network computing, can solve the problems of long inference time, affect performance, and increase the chip area of large neural networks, so as to improve efficiency and real-time performance, reduce cache space, and reduce chip area. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0043] Specific embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. It should be understood that the specific embodiments described here are only used to illustrate and explain the present invention, and are not intended to limit the present invention.
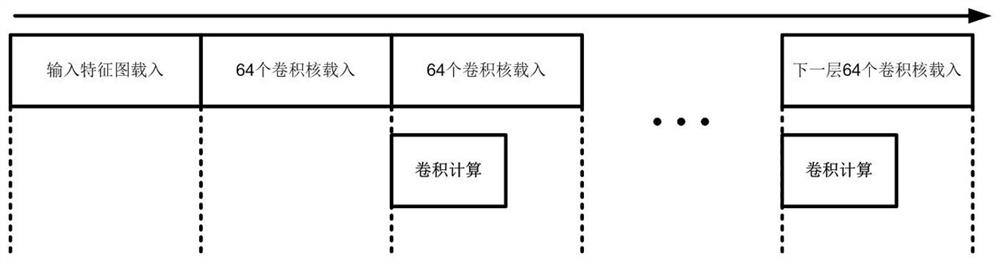
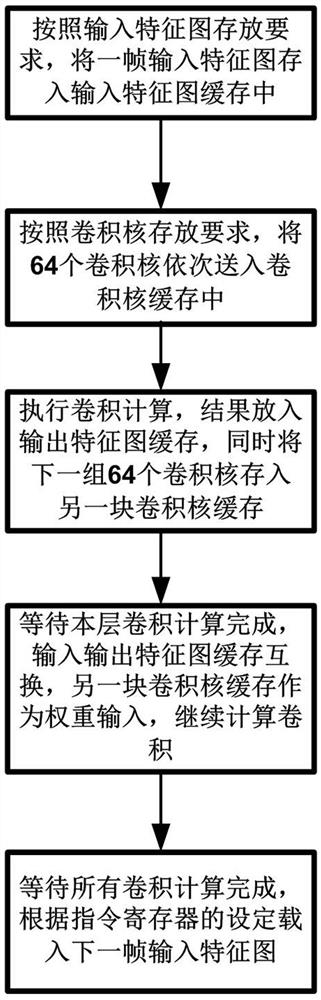
[0044] Such as figure 1 As shown, a neural network accelerator convolution calculation and data loading parallel scheme, including input feature map loading, 64 convolution kernel loading, 64 convolution kernel loading and convolution calculation, 64 next layer Convolution kernel loading and convolution calculation.
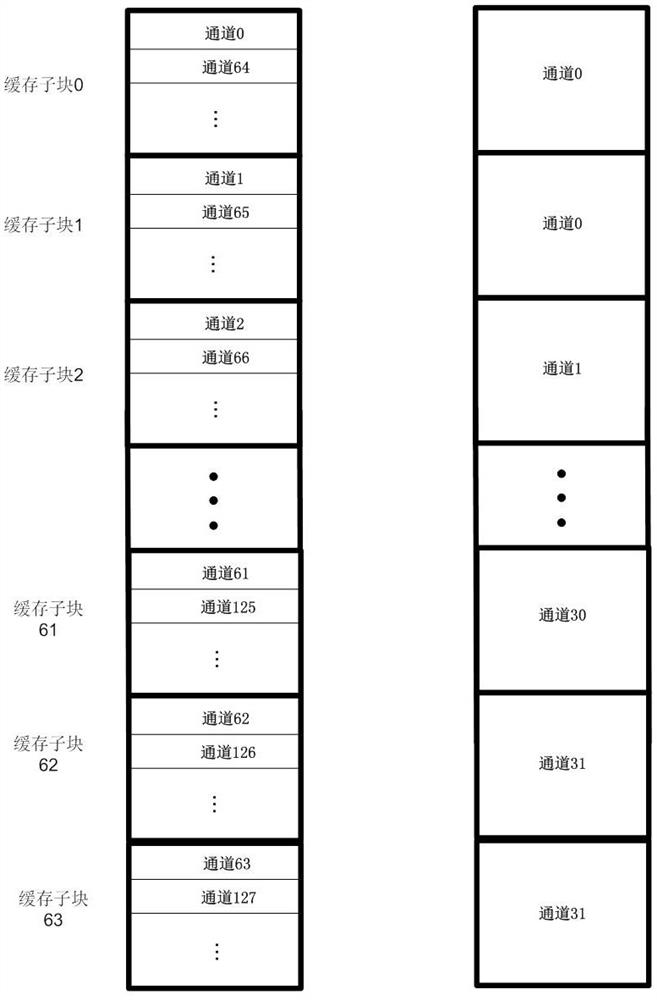
[0045]Input feature map loading includes all input feature map channels used for convolution calculation; 64 convolution kernel loading includes not only loading 64 convolution kernels, but also loading the total number of convolution kernels is less than 64 case; 64 convolution kernel loading and convolution calculations include parallel operati...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More