

A multi-user sharing-oriented multimedia network video recommendation method
A network video and recommendation method technology, which is applied in the field of big data multimedia network video applications, can solve problems such as user resentment and recommendation system accuracy reduction, so as to improve utilization, realize incremental update, and increase computing speed and computing resources. The effect of utilization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0089] The specific embodiments of the present invention will be further described in detail below in conjunction with the accompanying drawings.
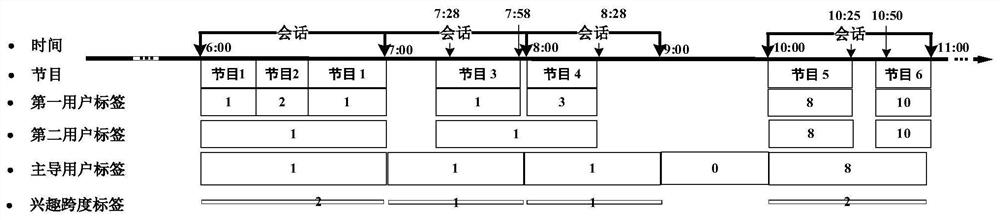
[0090] In this embodiment, the data set comes from the data of a certain operator's IPTV set-top box. Among them, 1100 user data were selected from the IPTV video system for a period of three months to watch records, which involved a total of 498,309 log records and 2830 programs.
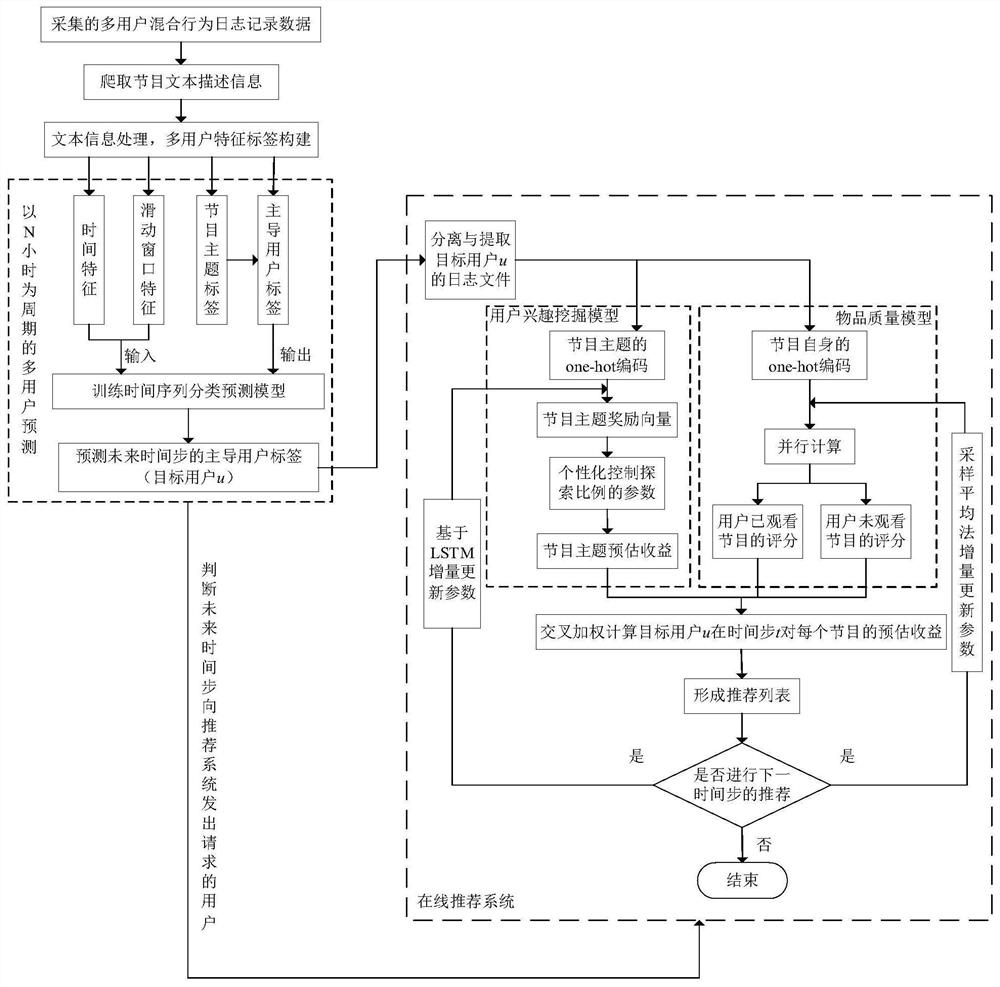
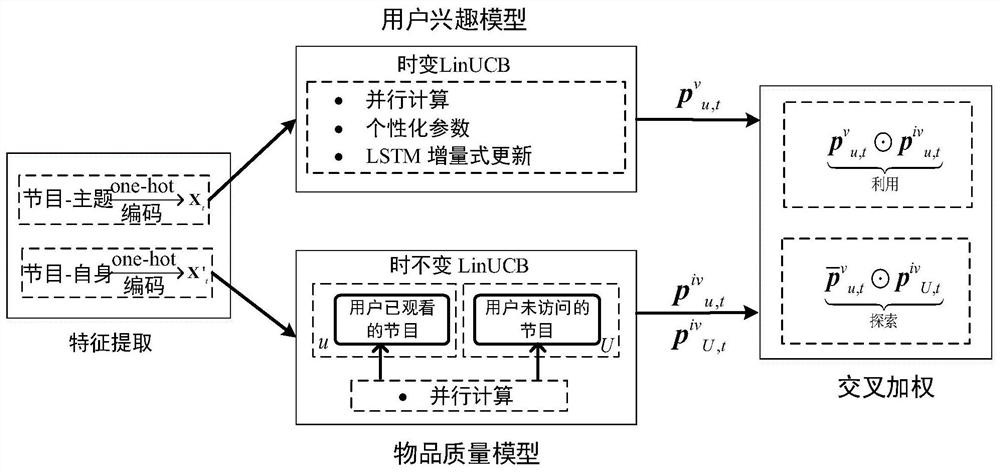
[0091] like figure 1 As shown, the present invention provides a kind of multimedia network video recommending method facing multi-user sharing, and the method comprises the following steps:
[0092] Step 1: Collect the multi-user mixed behavior log record data of multi-user watching online video, and process the multi-user mixed behavior log record data, including data cleaning, data integration and data resampling.
[0093] (1-1) IPTV set-top boxes are used to collect multi-user mixed behavior log record data of multi-user watching online video at an...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More