

Audio-driven face animation generation method and device, equipment and medium
A technology for driving face and animation, applied in the field of artificial intelligence, it can solve the problems of the complexity of the face image generation process, and achieve the effect of improving the generalization ability, reducing the production cost, and strengthening the generalization ability.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


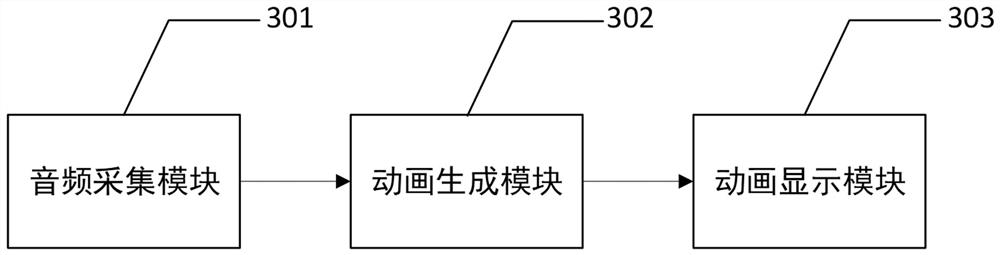
Examples
Embodiment Construction
[0037] In order to make the object, technical solution and technical effect of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments.
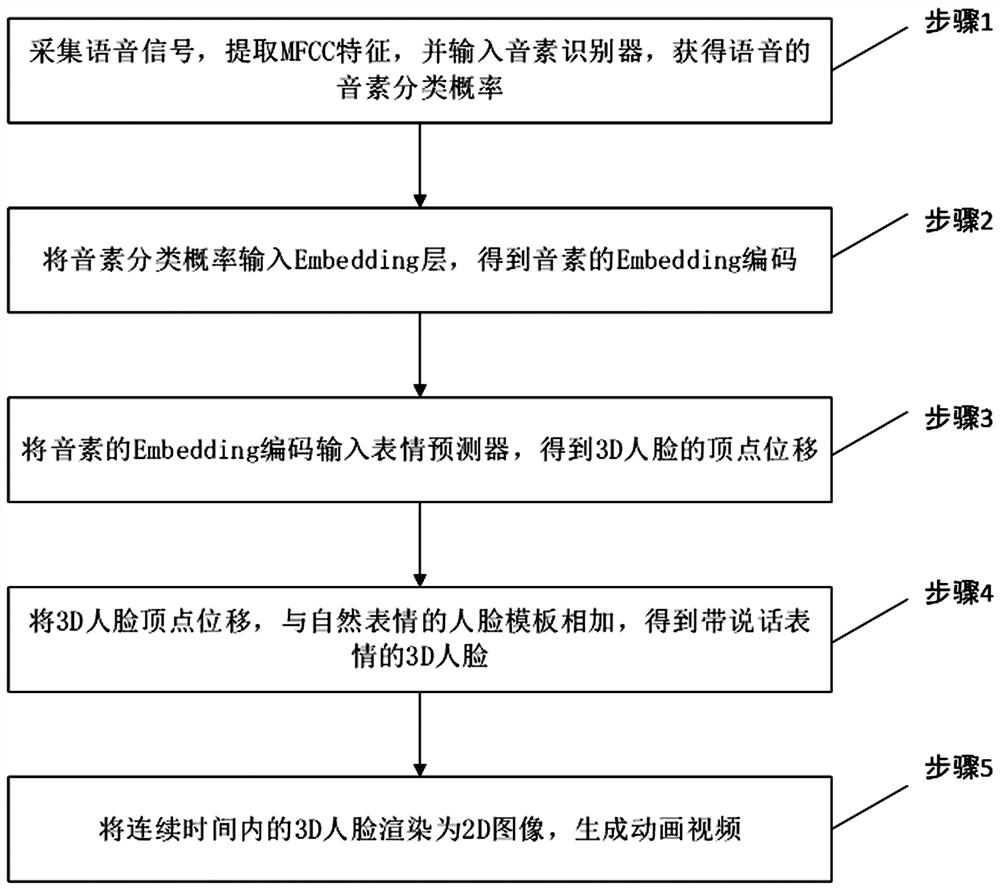
[0038] Such as figure 1 As shown, a cross-language audio-driven face animation generation method includes the following steps:
[0039] Step 1: collect speech signals, extract MFCC features, and input them into a phoneme recognizer to obtain phoneme classification probabilities of speech.
[0040] In this embodiment, the sampling rate is set to 8000Hz for the collected audio signal, and the sliding window size is set to 0.025s, the sliding window step is 0.01s, and the cepstrum number is 40, the MFCC features are extracted, and the obtained MFCC features Every 3 are stacked, and the length of the MFCC feature obtained for each frame is 120, and then input into the phoneme recognizer for phoneme recognition.
[0041] The output of the phonem...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More