Video text similarity measurement method and system
A similarity measurement and video technology, applied in the similarity measurement method and system field of video text, can solve the problems of increasing the burden of computer hardware, strengthening compactness, etc., and achieve the effect of narrowing the semantic gap, relieving pressure, and accelerating processing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
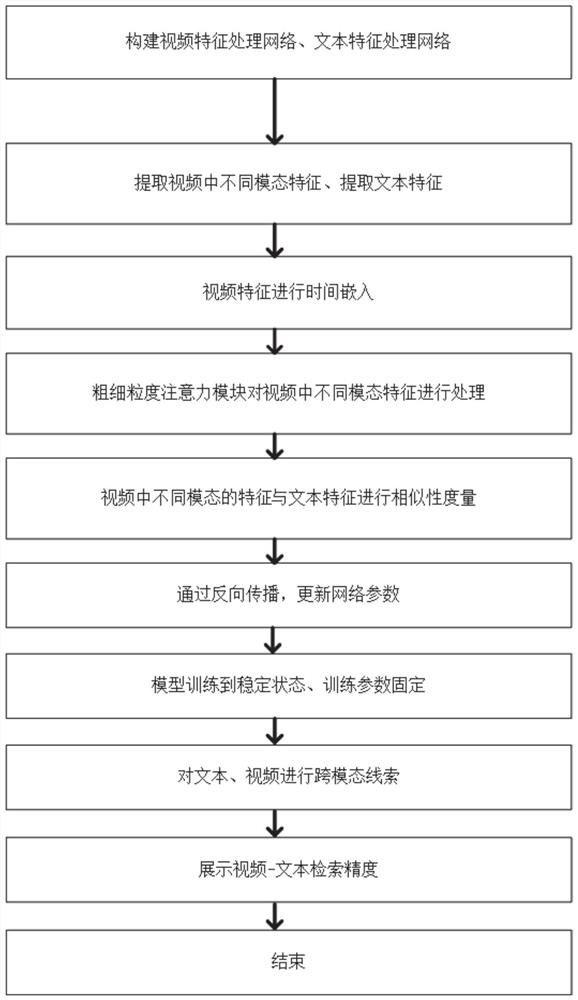
[0055] See attached figure 1 ,2 As shown, this embodiment discloses a similarity measurement method for video text, including:
[0056] Video feature processing network:
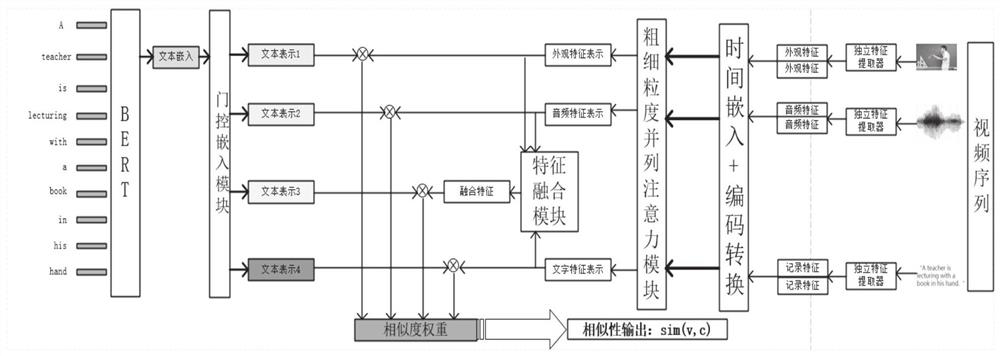
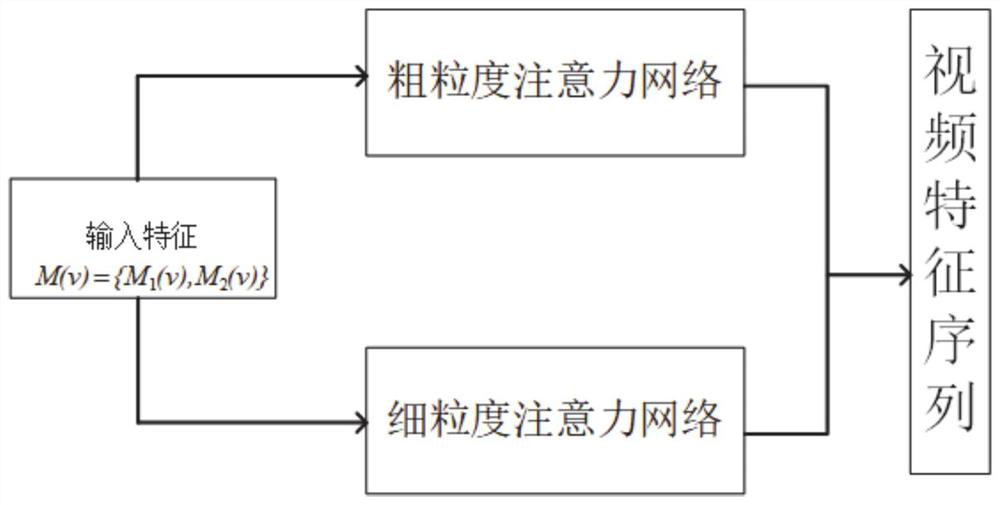
[0057] First, in this embodiment, a pre-trained feature extractor is used to extract multimodal features of a video to obtain an initial video feature representation. Second, the initial features are fed into a coarse-fine-grained parallel attention network to obtain intermediate representation features. Again, the intermediate feature representation is input to the feature fusion module to obtain the final video multimodal feature representation.
[0058] Text feature processing network:
[0059] The input text is processed through the pre-trained BERT model, and finally the text feature representation is obtained. Then the text feature representation vectors corresponding to different modal features of the video are generated through the gate embedding module.
[0060] Video-text cross-modal retrieval...
Embodiment 2
[0120] The purpose of this embodiment is to provide a computing device, including a memory, a processor, and a computer program stored in the memory and operable on the processor, and the processor implements the steps of the above method when executing the program.
Embodiment 3
[0122] The purpose of this embodiment is to provide a computer-readable storage medium.
[0123] A computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, the steps of the above-mentioned method are executed.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More