

Lempel-Ziv data compression technique utilizing a dictionary pre-filled with frequent letter combinations, words and/or phrases
a data compression and dictionary technology, applied in the field of textual data compression, can solve the problems of not taking advantage of the fact that the similarity of texts is greater, failing to teach the identification of the most appropriate library of text or the genre of the document, and achieving the effect of improving compression and benefi
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
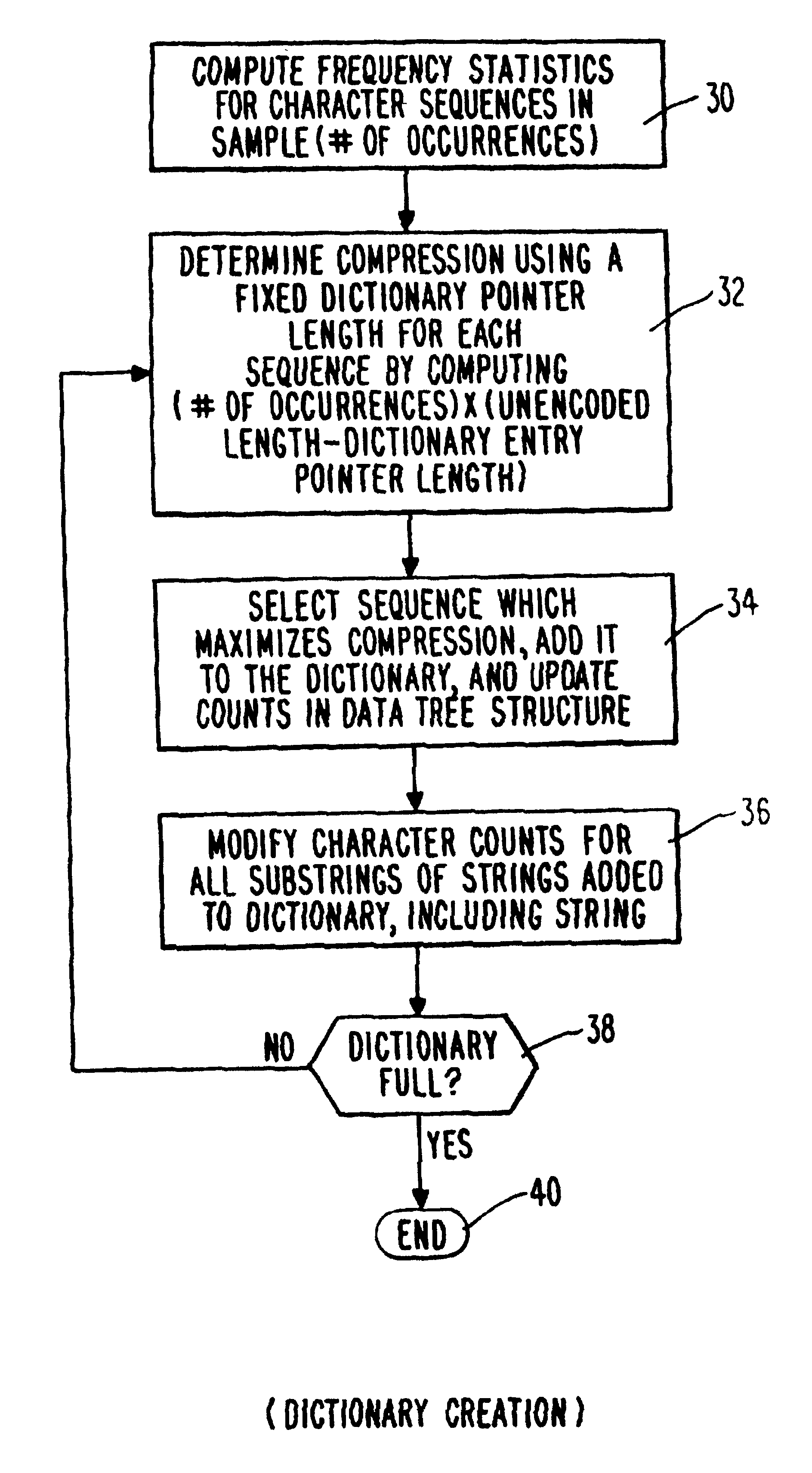
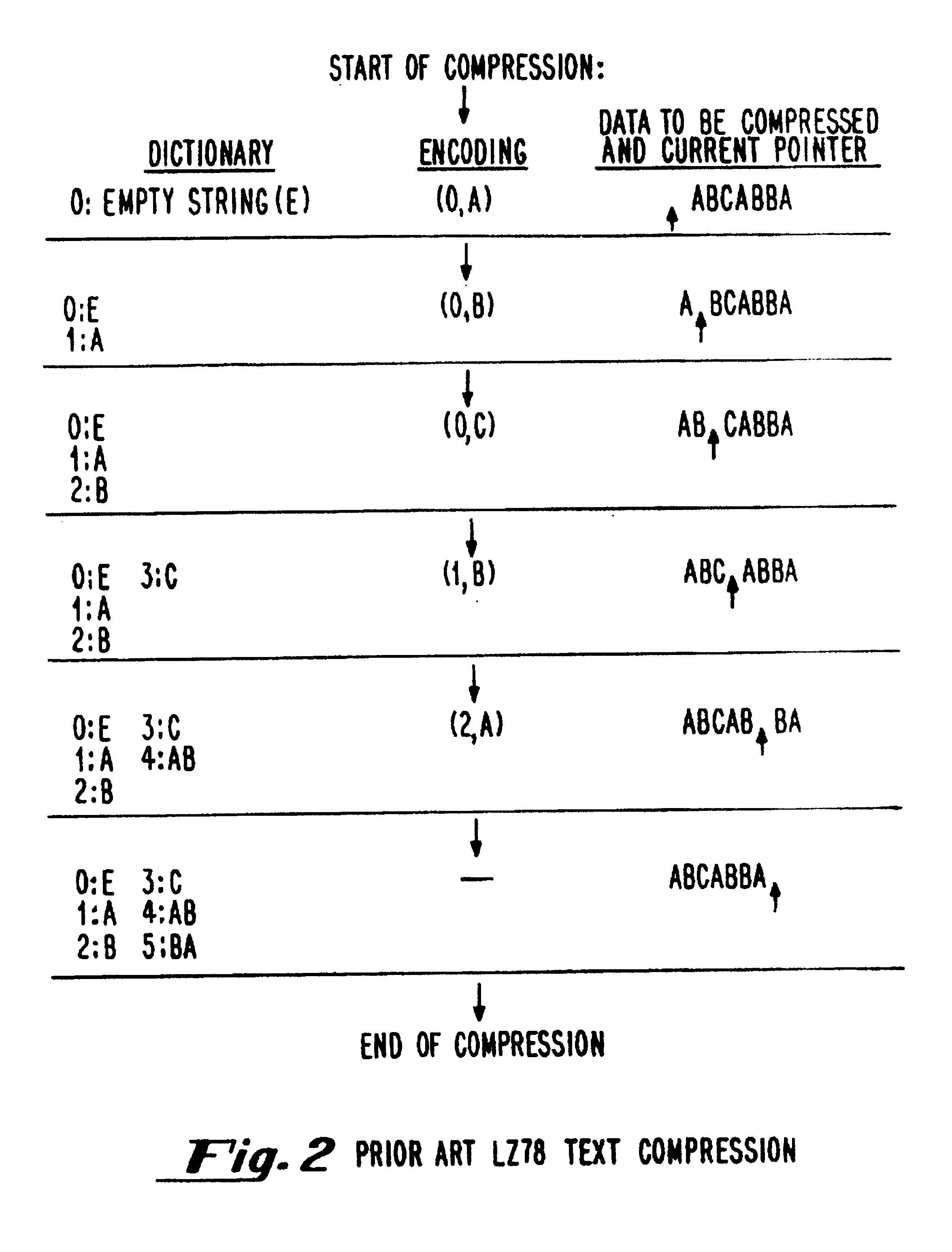
[0059]The present invention will be described in detail below with respect to FIGS. 4-14. Those skilled in the art will appreciate that the description given herein is for explanatory purposes only and is not intended to limit the scope of the invention. Accordingly, the scope of the invention is only to be limited by the scope of the appended claims.
[0060]The extension to the Lempel-Ziv algorithms in accordance with the invention can be used in conjunction with all of the known variants of the Lempel-Ziv compression techniques described in the patent literature as well as in the text compression literature. However, in presently preferred embodiments, the present invention is used as a modification to the LZ77 or LZ78 compression techniques or as a modification to a Lempel-Ziv variant which is itself a modification to or extension of the LZ77 or LZ78 techniques. The extension to the Lempel-Ziv algorithms in accordance with the invention is preferably implemented as part of a softwa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More