

Verification method and device for speaker authentication and speaker authentication system
A technology for speaker authentication and verification devices, which is applied in speech analysis, instruments, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
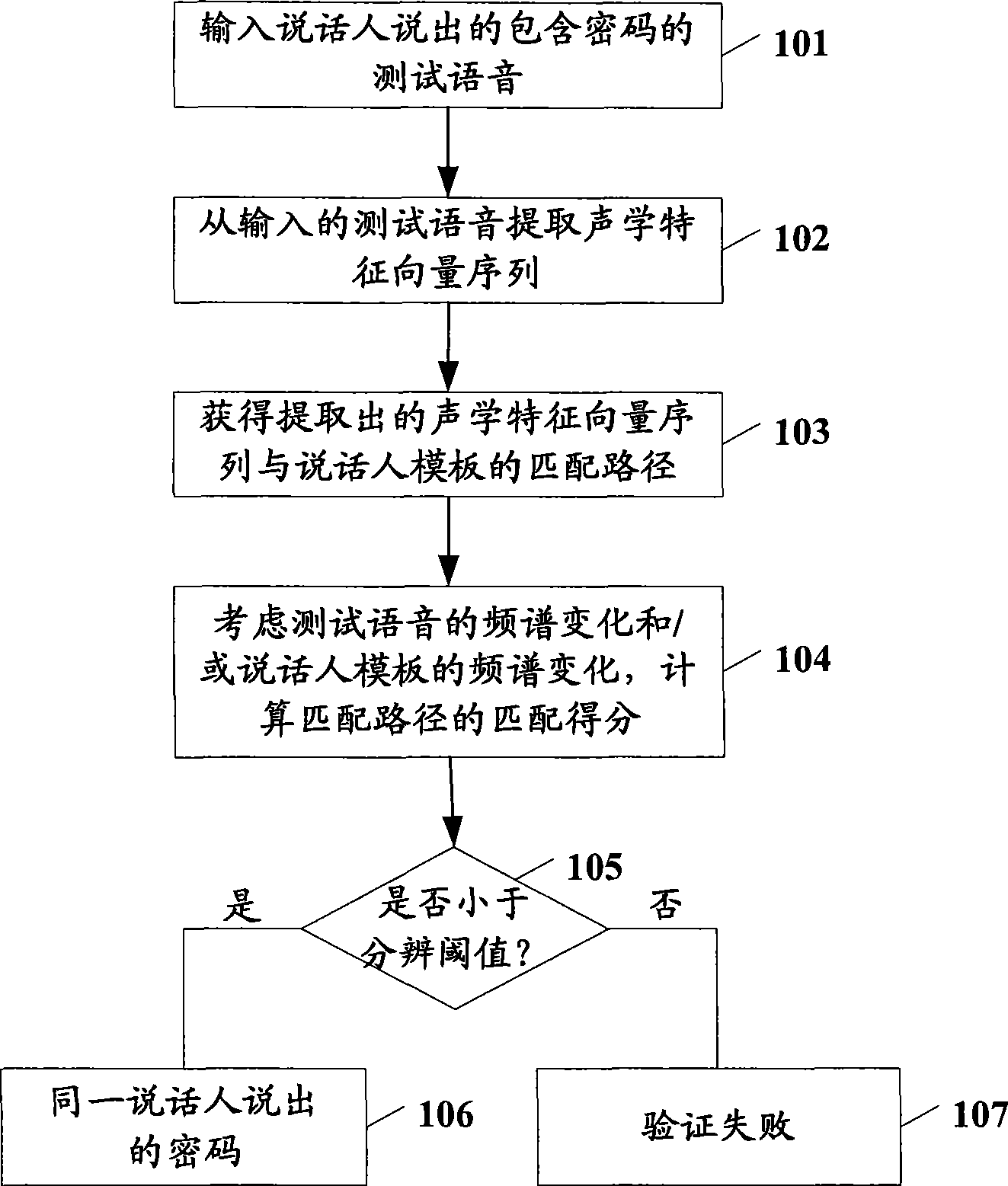
[0024] figure 1 is a flow chart of the verification method for speaker authentication according to the first embodiment of the present invention.
[0025] The present embodiment will be described below with reference to this figure.
[0026] Such as figure 1 As shown, firstly in step 101, a test voice including a password is input by the user performing verification. Wherein, the password is a specific phrase or pronunciation sequence set by the user in the registration stage for verification.
[0027] Next, in step 102, a sequence of acoustic feature vectors is extracted from the test speech input in step 101. The present invention is not particularly limited to the manner of expressing acoustic features, for example, MFCC (Mel-scale Frequency Cepstral Coefficients, Mel cepstral coefficients), LPCC (Linear Prediction Cepstrum Coefficient, linear prediction cepstral coefficients) or other based on Various coefficients obtained from energy, pitch frequency, or wavelet analy...
example 1
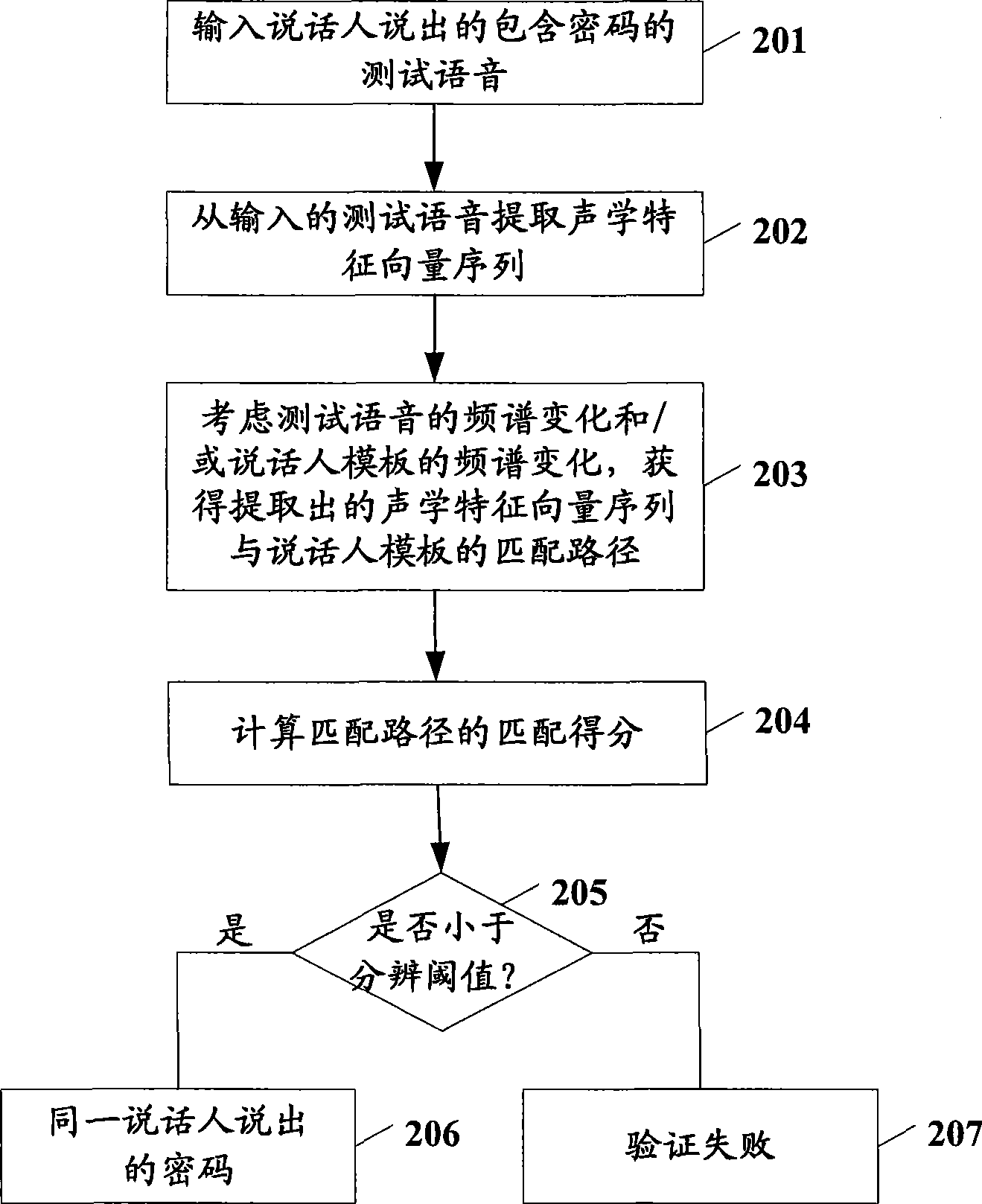
[0040] In Example 1, the weight of each frame on the matching path is measured based on the feature distance between the target frame and its adjacent frames in time series.
[0041] First, the spectral changes are measured for each frame of speaker template X and test speech Y, respectively.
[0042] Specifically, formula (1) is used to calculate the spectral change d of the speaker template X x (i):
[0043] d x (i)=(dist(x i , x i-1 )+dist(x i , x i+1 )) / twenty one)
[0044] where i is the index of the frame of the speaker template X, x is the feature vector in the speaker template X, and dist refers to the feature distance between two vectors, e.g., Euclidean distance.
[0045] It should be understood that although formula (1) is used here, the feature distance dist(x i , x i-1 ) and dist(x i , x i+1 ) to measure the spectral change of the speaker template X, but the present invention is not limited thereto, and the feature distance dist(x i , x i-1 ) and dist...
example 2
[0054] In Example 2, the weights of each frame on the matching path are metric-matched based on segmentation processing using codebooks.
[0055] The codebook used in this embodiment is a codebook trained in the acoustic space of the entire application, for example, for the Chinese language application environment, the codebook needs to be able to cover the acoustic space of Chinese speech; for the English language application environment For example, the codebook needs to be able to cover the acoustic space of English speech. Of course, for some special-purpose application environments, the acoustic space covered by the codebook can also be changed accordingly.
[0056] The codebook in this embodiment includes multiple codewords and feature vectors corresponding to each codeword. The number of codewords depends on the size of the acoustic space, the desired compression ratio and the desired compression quality. The larger the acoustic space, the larger the number of codewor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More