

Auto recommending method of urban power load forecasting module based on associative rules
A prediction model and power load technology, which is applied in the field of automatic recommendation of urban power load prediction models based on association rules, can solve the problems of urban power load calculation, models cannot be considered, etc., and achieve credible prediction results, strong credibility, guidance The effect of urban power grid planning
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
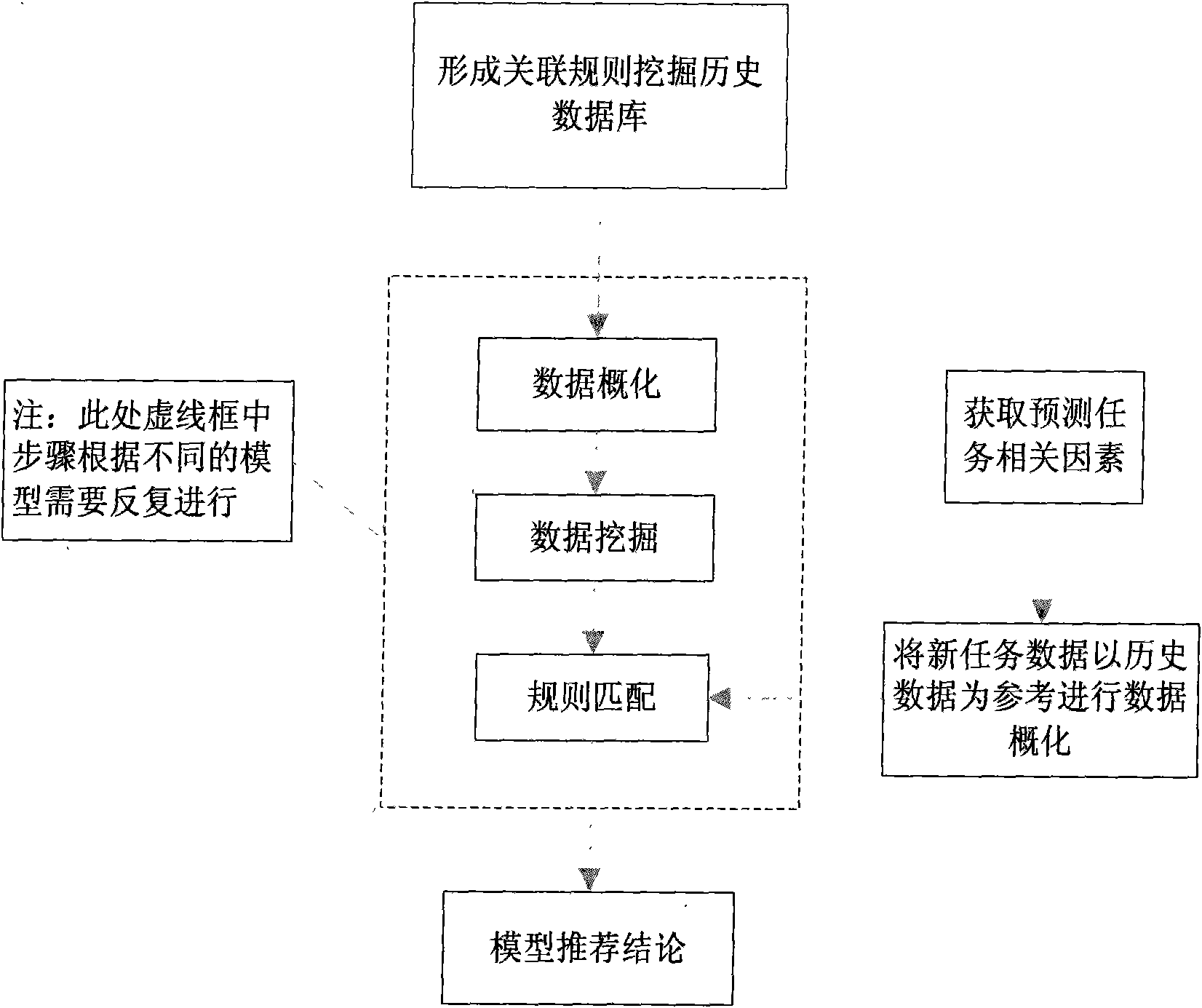
[0020] The automatic recommendation method of the present invention will be described in detail below.
[0021] 1. Construction of historical case database
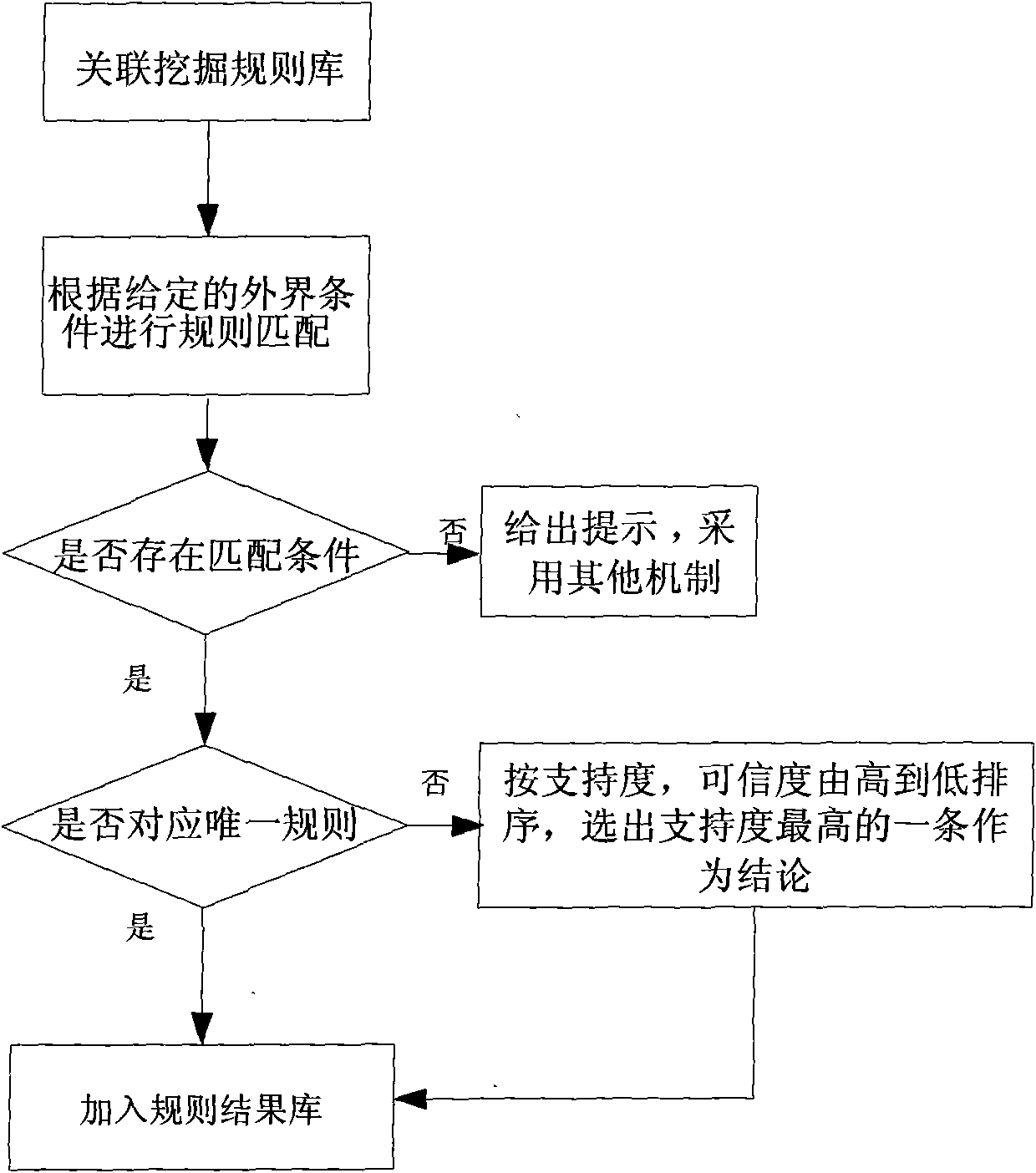
[0022] To recommend a suitable model, a historical database must first be established. The original data provided for the present invention come from the planning-related data of a large number of cities in China, mainly including: historical load data of previously predicted regions, data of related factors, such as the proportion of the secondary industry, city type , urban administrative functions, urban population development, urban load development status, forecast time limit, urban GDP development level, etc. In order to obtain accurate and reasonable conclusions, the applicability of the model is also analyzed as a continuous quantity. Here, the applicability of the model is set as a value between 0 and 1, where 0 is the lowest level of applicability, indicating that the model is not applicable ; 1 is the highest ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More