

Embedded Chinese-English mixed voice recognition method and system for non-specific people
A non-specific person, mixed voice technology, applied in voice recognition, voice analysis, instruments, etc., can solve problems such as voice recognition cannot be realized, and achieve the effect of low algorithm pressure, high recognition rate, and small storage space
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0053] The present invention will be further described below in conjunction with the accompanying drawings.
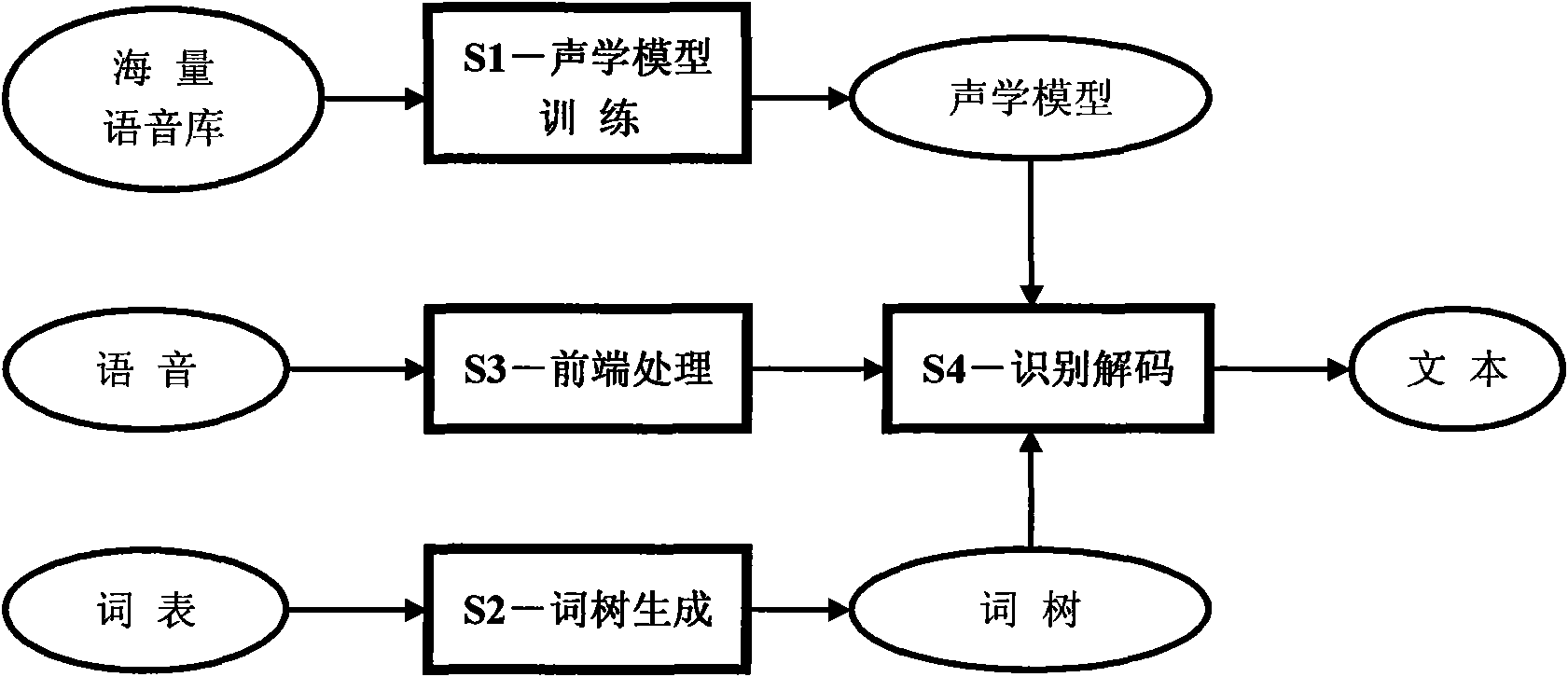
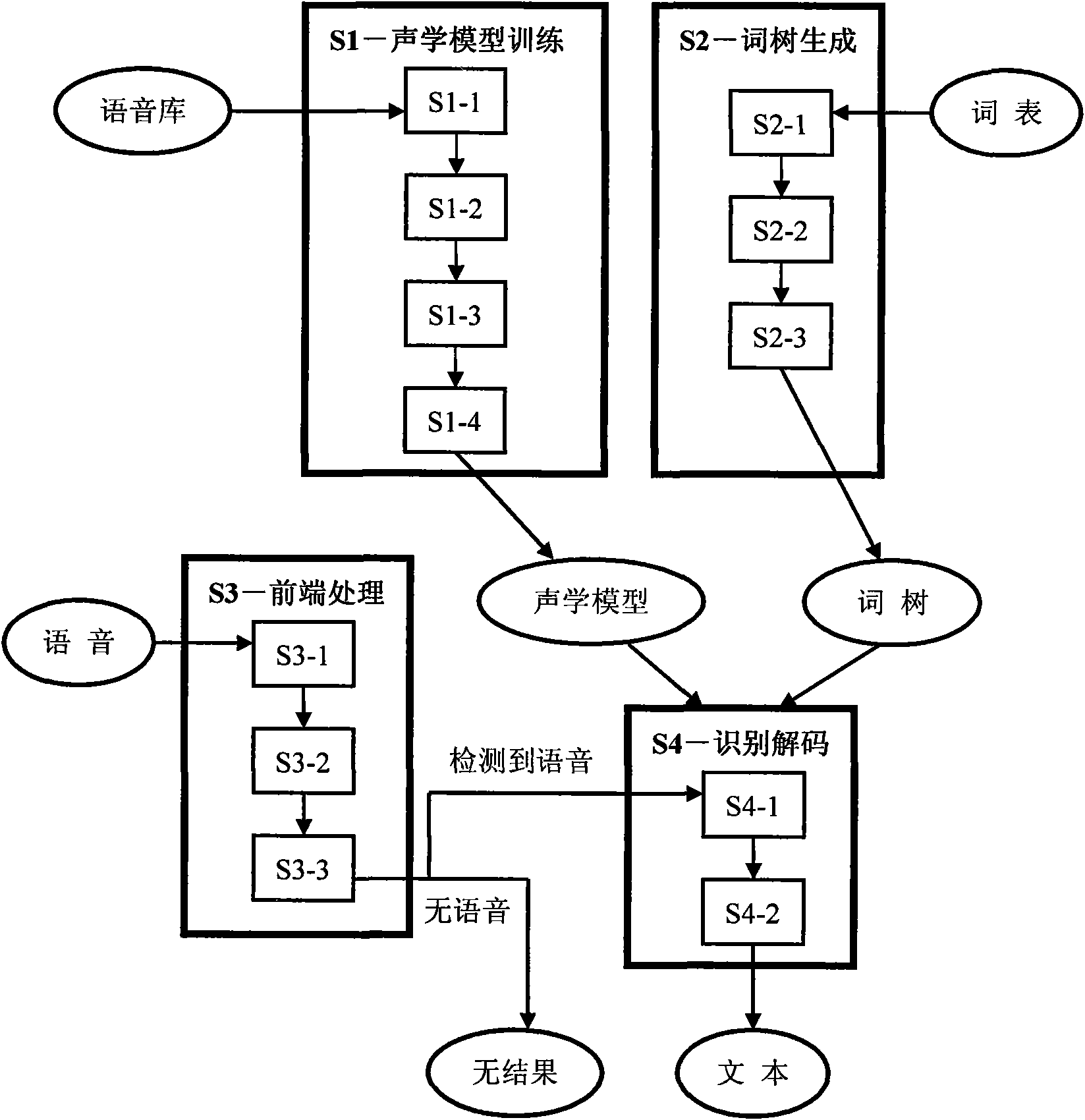
[0054] figure 1 It is a schematic diagram of the framework of the present invention, image 3 It is a schematic flow chart of the system of the present invention, such as figure 1 and image 3 As shown, this system is mainly composed of four parts: S1-acoustic model training, S2-word tree generation, S3-front-end processing, and S4-recognition and decoding. The system flow is as follows:
[0055] The S1-acoustic model training part of the process is as follows:
[0056] 1. S1-1, feature extraction. According to the frame length of 25 milliseconds and the frame shift of 10 milliseconds, the 12-dimensional MFCC features are extracted, and the 1-dimensional energy features are added to form a total of 13-dimensional static features. The dynamic features take the first-order and second-order difference features to obtain a 39-dimensional acoustic feature vector sequen...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More