

Method for extracting content of web page
A webpage and text technology, applied in the field of webpage text extraction, can solve the problems of inability to extract precision, adaptability of extraction speed, flexibility and meet actual needs at the same time, achieve the effect of simple and intuitive features, low maintenance cost, and fast implementation speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
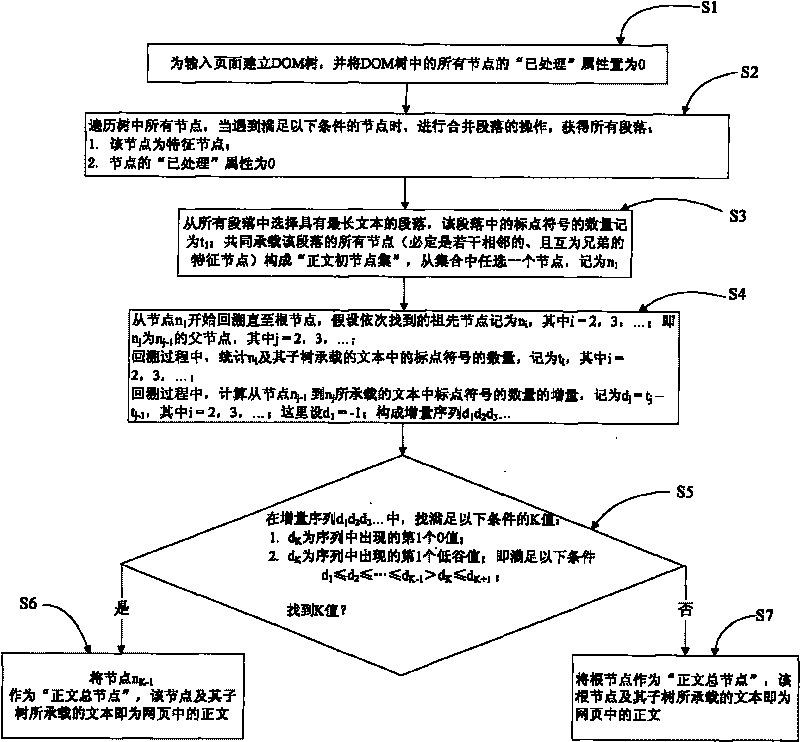
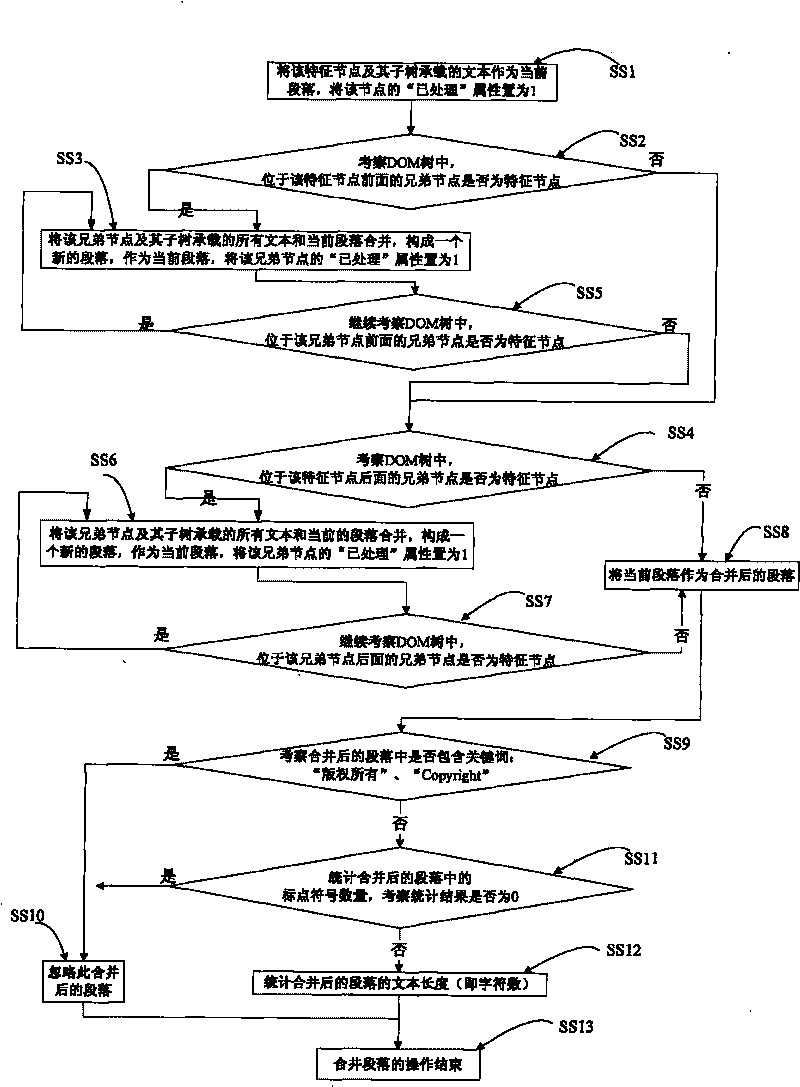
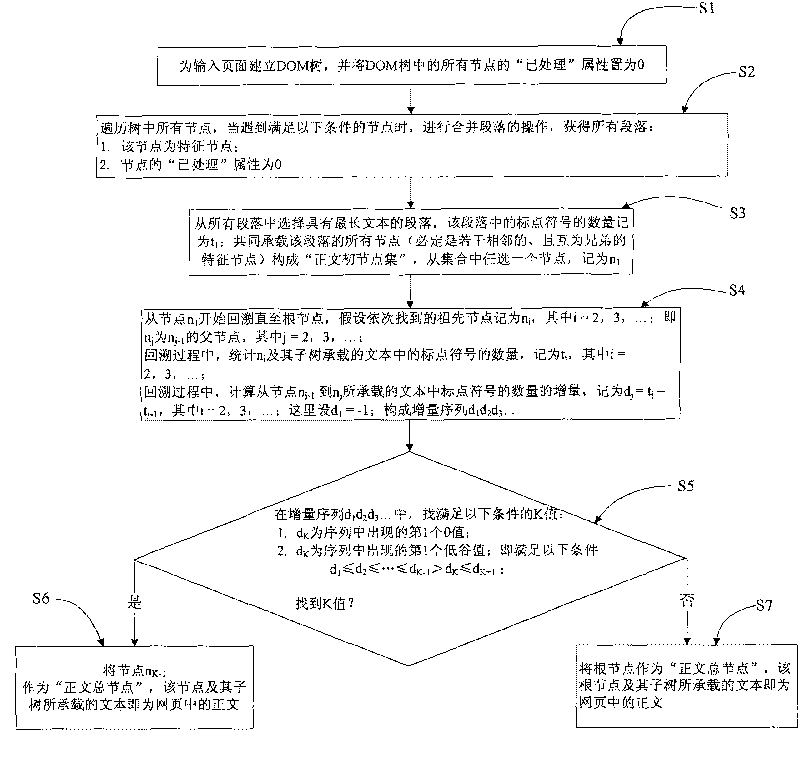
[0043] In order to make the object, technical solution and advantages of the present invention clearer, a web page text extraction method of the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
[0044] The webpage to be extracted carries a lot of information, including text title, text source, text release time, text, author and other information, as well as other noise information, such as navigation information, advertisement information, copyright information and related links. Preferably, there are few or no punctuation marks (especially commas and periods) in the noise information such as navigation information in the webpage, while there are more punctuation marks (especially commas and periods) in the text information. For example, a news web pag...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More