Method and system for implementing repeated data deletion
A technology for duplicating data and data, which is applied to the redundancy in operations for data error detection, electrical digital data processing, special data processing applications, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0019] In order to enable those skilled in the art to better understand the solutions of the embodiments of the present invention, the embodiments of the present invention will be further described in detail below in conjunction with the drawings and implementations.
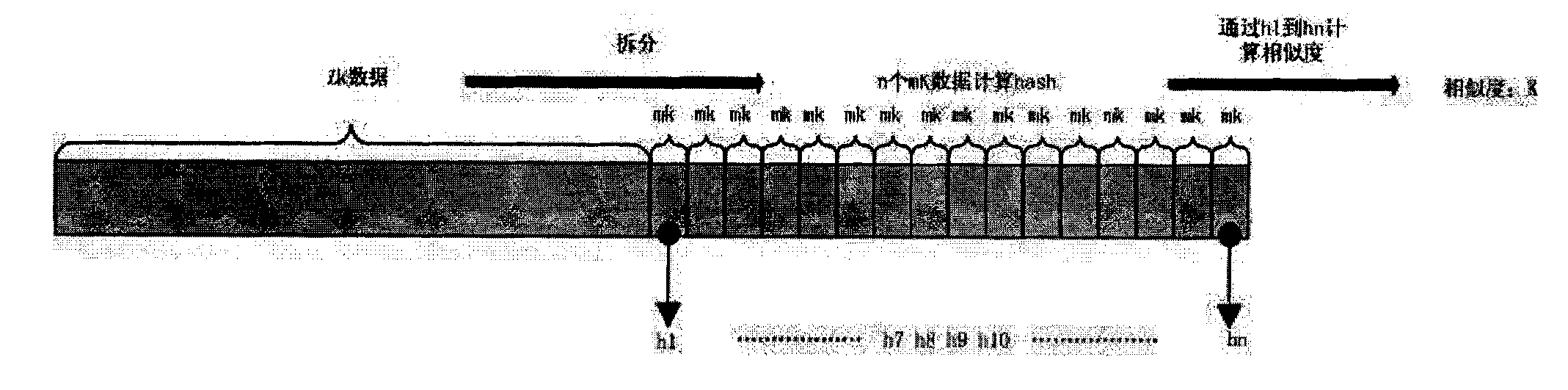
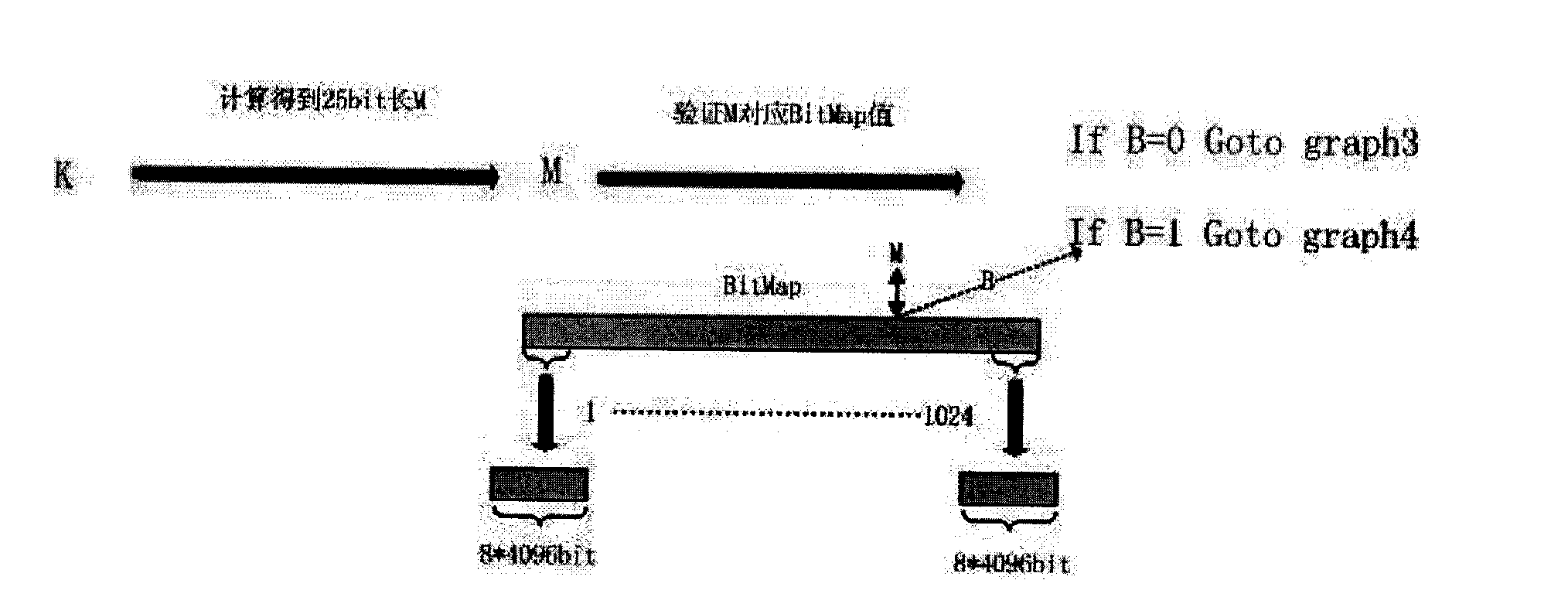
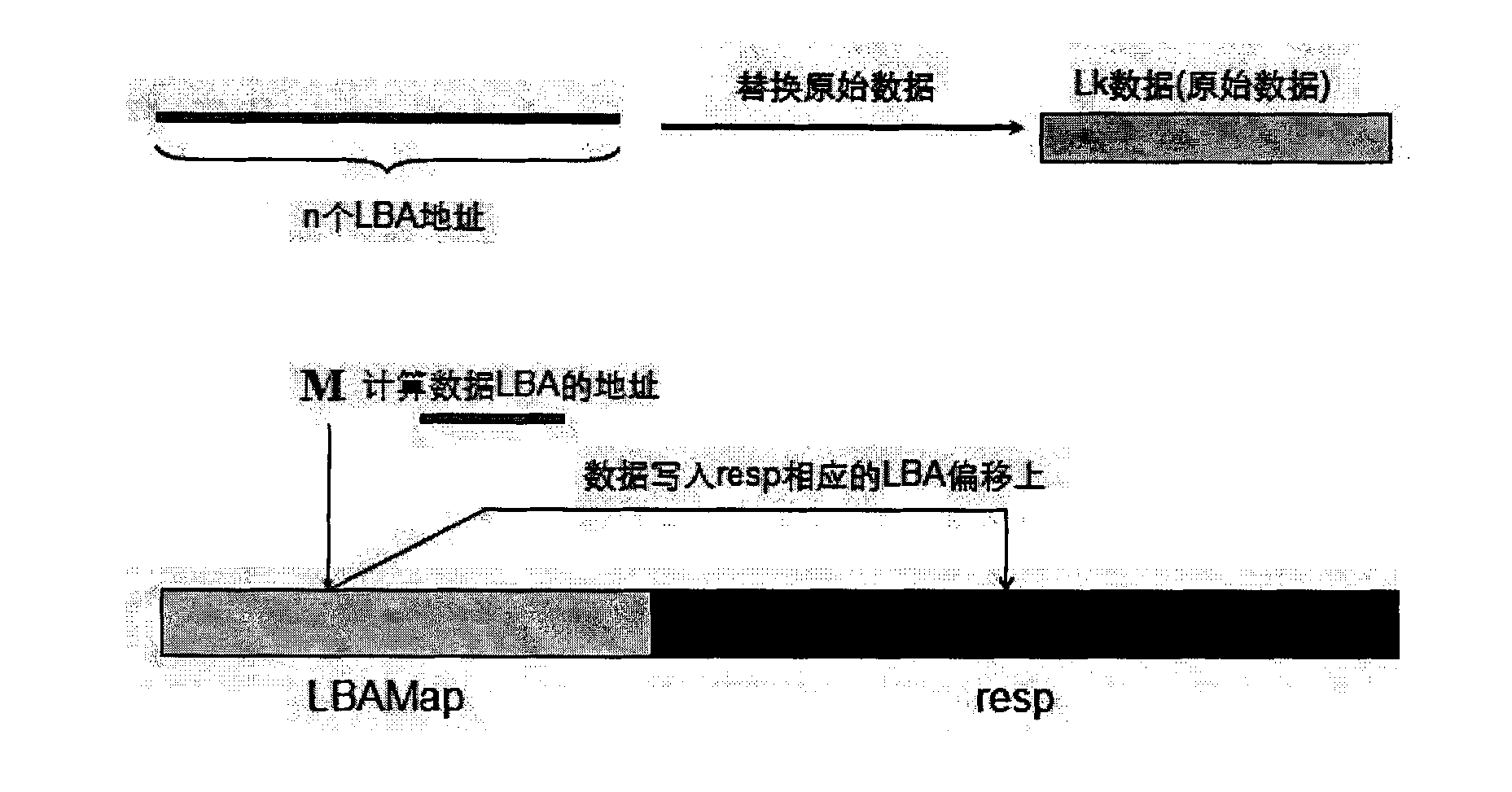
[0020] To achieve deduplication, it is necessary to find the same data, then build a high-speed index, and use the index to replace the same data. The key points of realization are how to find the same data, and how to build a fast index. The traditional data deduplication technology marks by calculating the hash value of the data, and maintains the index through a large number of caches. It is difficult to achieve fast indexing, and if the hash value is used as the data fingerprint, hash conflicts are inevitable. Although the probability is very low, once it occurs, it will cause unpredictable data errors.
[0021] The principle of the Simhash (similarity hash) algorithm is: each token in the data is mapped to ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More