

Massive data aggregation method and system based on cloud computing platform
A cloud computing platform and massive data technology, applied in the field of massive data aggregation methods and systems, can solve the problem that data classification cannot meet practical applications, and achieve the effect of efficient clustering
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] The present invention will be described more fully hereinafter with reference to the accompanying drawings, in which exemplary embodiments of the invention are illustrated.
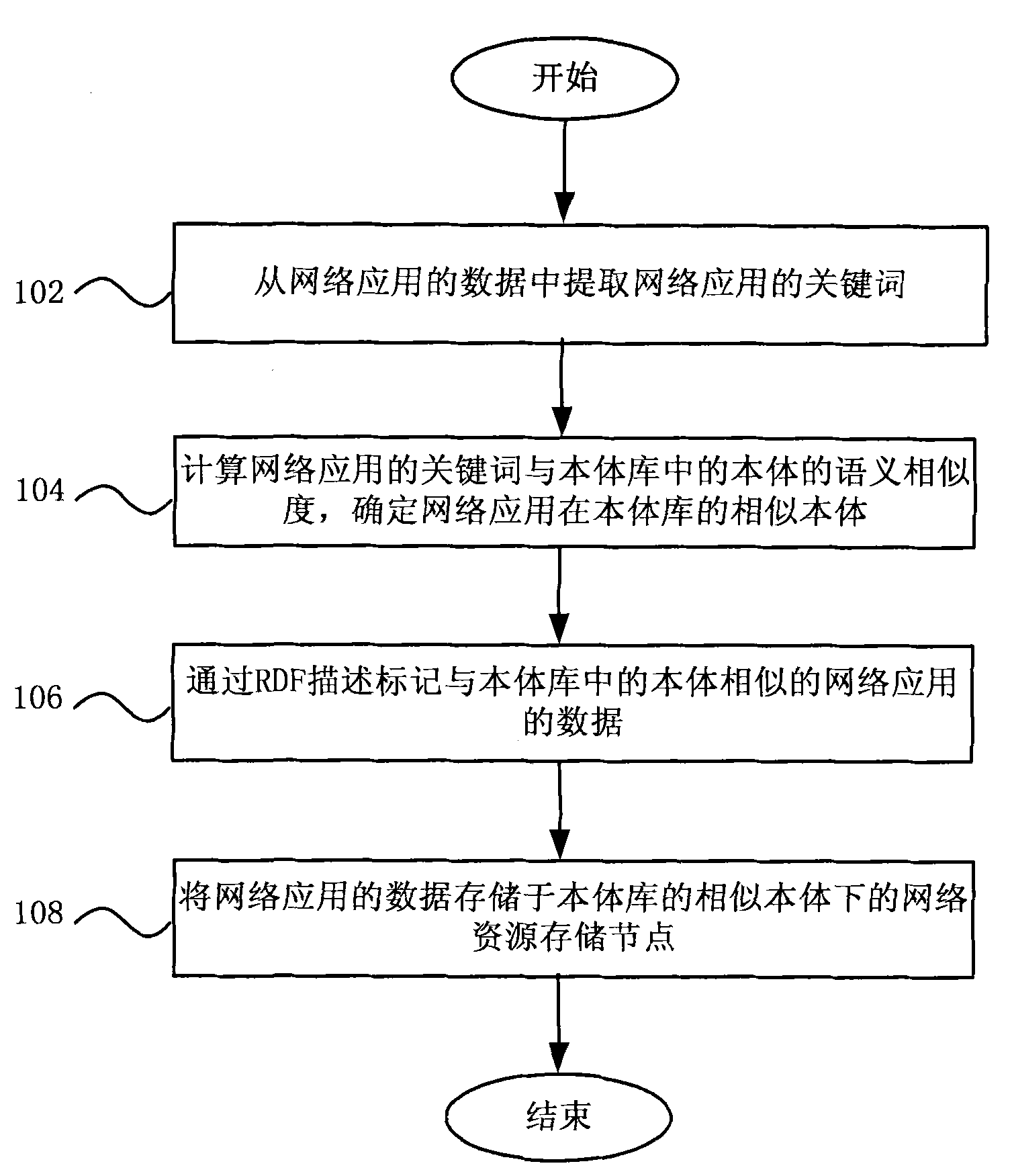
[0048] figure 1 A flowchart showing an embodiment of the cloud computing platform-based massive data aggregation method of the present invention.
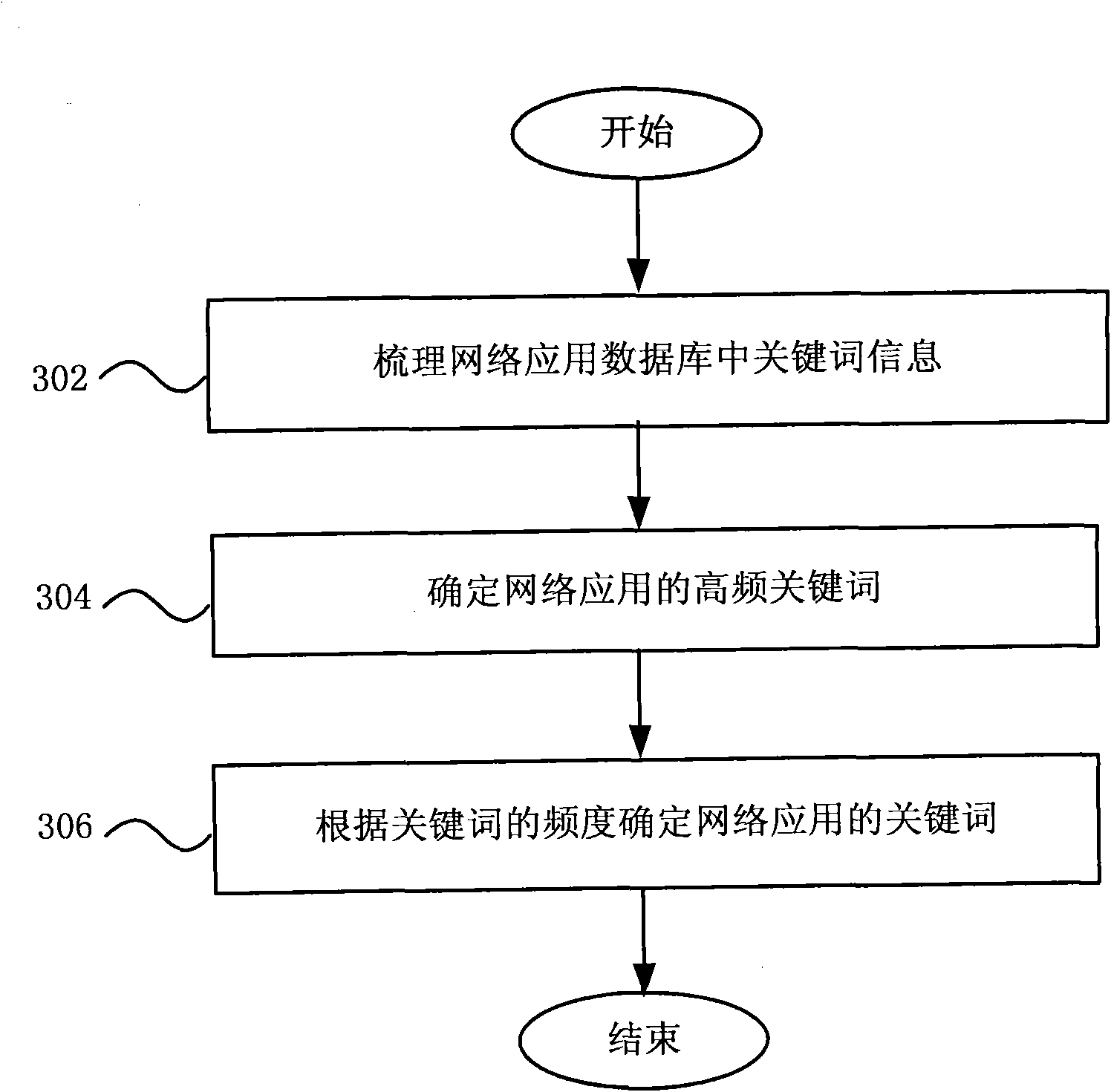
[0049] Such as figure 1 As shown, in step 102, keywords of the network application are extracted from the data of the network application. Based on the network application, sort out the keyword information in the application database to obtain the keywords of the network application.
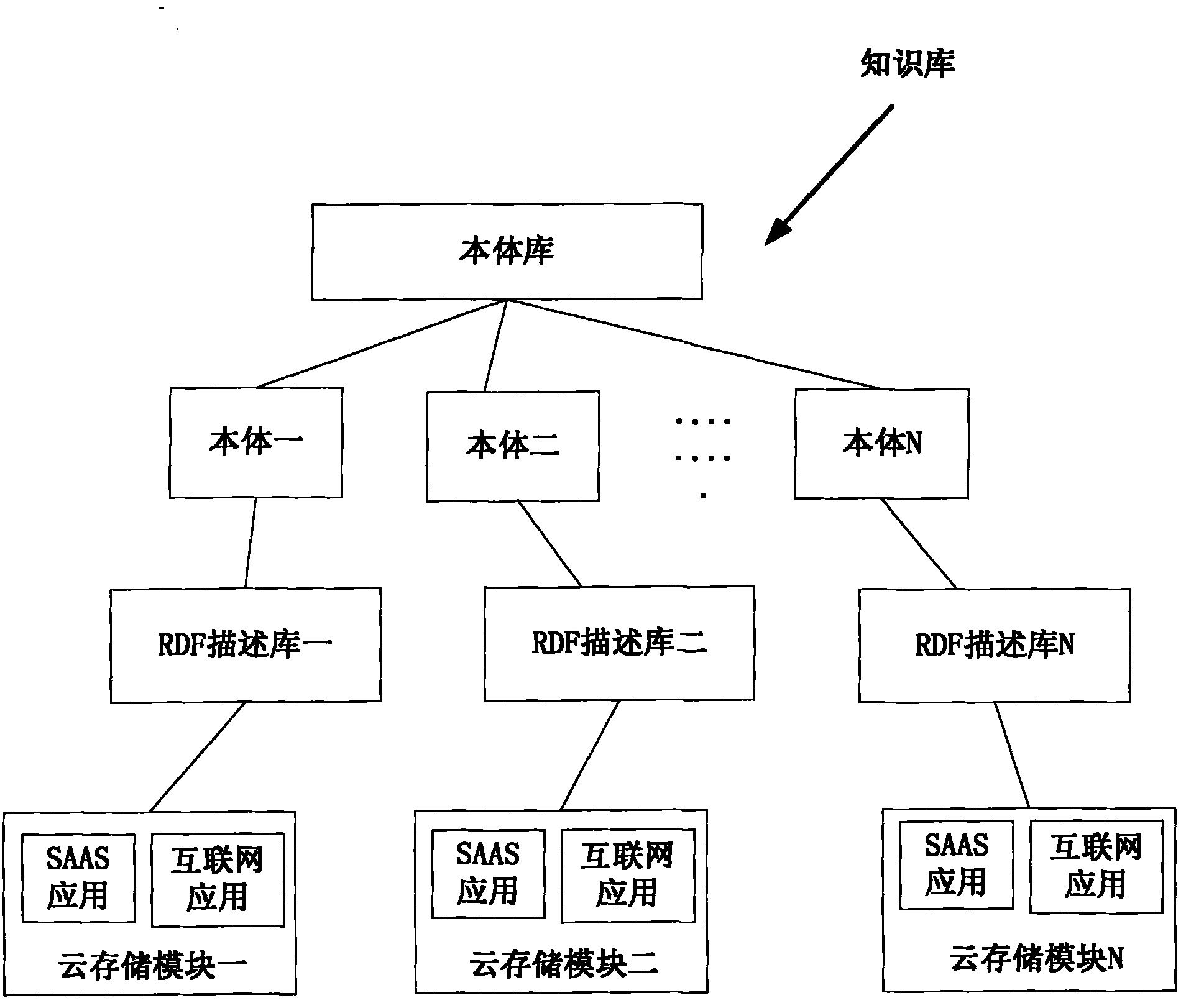
[0050] In step 104, the semantic similarity between the keyword of the network application and the ontology in the ontology database is calculated, and the similar ontology of the network application in the ontology database is determined. Semantic similarity can be obtained through semantic distance calculation. There are many algorithms for semantic distance calculat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More