Clustering method and system
A clustering method and clustering technology, applied in the field of data processing, can solve the problems of reduced clustering operation performance and increased computing time, and achieve the effect of reducing the number of comparisons, reducing the burden, and improving the operation performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
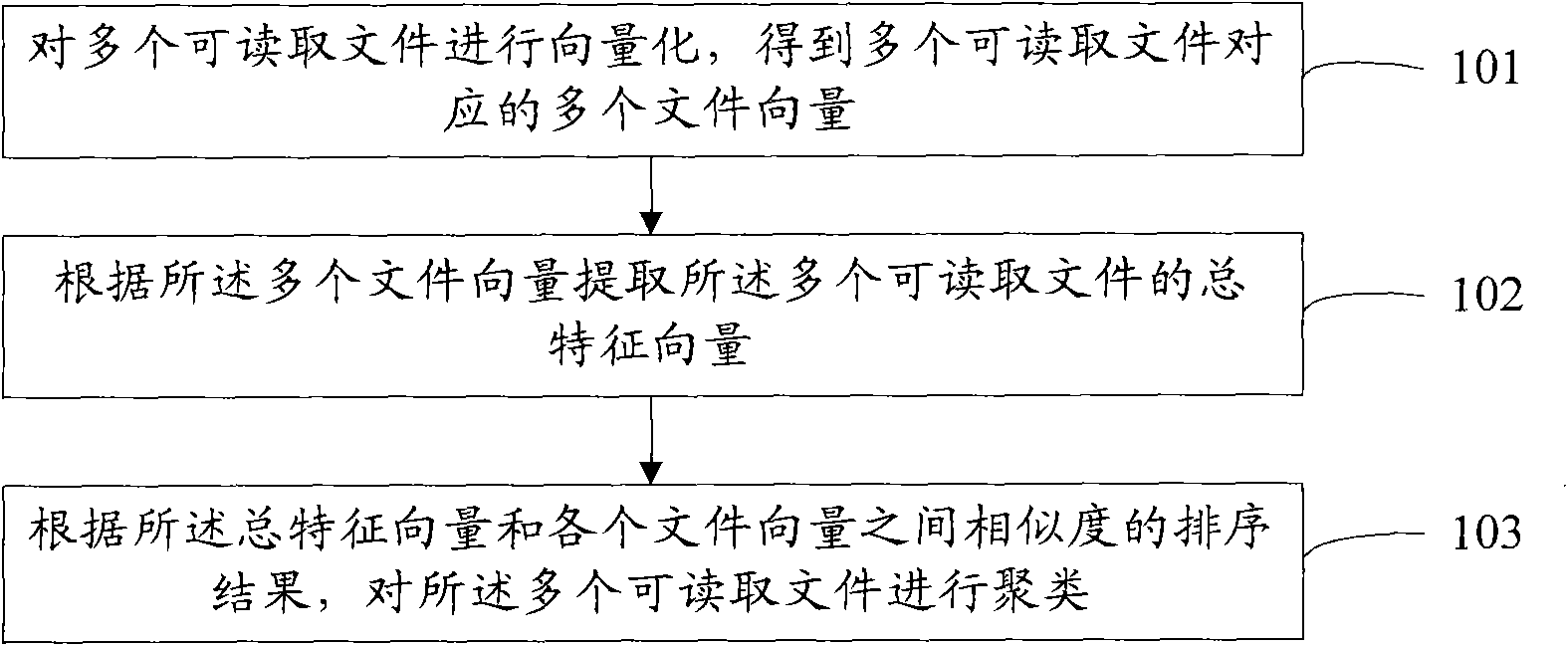
[0111] Corresponding to the method provided in Embodiment 1 of a clustering method of the present application, see Figure 4 , the present application also provides a clustering system embodiment 1, in this embodiment, the system may include:
[0112] The vectorization unit 401 is configured to vectorize multiple readable files to obtain multiple file vectors corresponding to the multiple readable files.
[0113] In this embodiment, the readable files can be files in various formats converted into vectors, for example, Word documents, Excel tables, etc.; Convert the multiple readable files into corresponding multiple file vectors. The vectorization is to convert a readable file into a vector composed of a series of numbers, where each number represents a value corresponding to a different feature. The vectors corresponding to different readable files are different. The file vector in this application means vector, and it is called a file vector to distinguish it from subseq...
Embodiment 2
[0119] Corresponding to the method provided in Embodiment 2 of a clustering method of the present application, see Figure 5, the present application also provides a preferred embodiment 2 of a clustering system. In this embodiment, the system may specifically include:
[0120] The vectorization unit 401 is configured to vectorize multiple readable files to obtain multiple file vectors corresponding to the multiple readable files.
[0121] The extraction unit 402 is specifically configured to sequentially add and sum the eigenvalues of the common features of the multiple file vectors to obtain the corresponding eigenvalues of the total eigenvectors.
[0122] The first calculation unit 501 is configured to respectively calculate the first similarity between the plurality of file vectors and the total feature vector.
[0123] The first sorting unit 502 is configured to sort the multiple file vectors for the first time according to the first similarity.
[0124] The second ...
Embodiment 3
[0131] Corresponding to the method provided in Embodiment 3 of a clustering method of the present application, see Figure 5 , the present application also provides a preferred embodiment 3 of a clustering system. In this embodiment, the system may specifically include:
[0132] A vectorization unit 401, configured to vectorize multiple readable files to obtain multiple file vectors corresponding to multiple readable files;
[0133] The extraction unit 402 is specifically configured to sequentially add and sum the eigenvalues of the common features of the multiple file vectors to obtain the corresponding eigenvalues of the total eigenvectors.
[0134] The first calculation unit 501 is configured to respectively calculate the first similarity between the plurality of file vectors and the total feature vector.
[0135] The first sorting unit 502 is configured to sort the multiple file vectors for the first time according to the first similarity.
[0136] The second calcula...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com