Massive data storage and retrieval method
A technology of massive data and data, applied in the field of data processing, to achieve good retrieval (read) performance, increase the number, and reduce server IO pressure.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0015] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
[0016] The mass data storage and retrieval method of the present invention comprises the following steps:
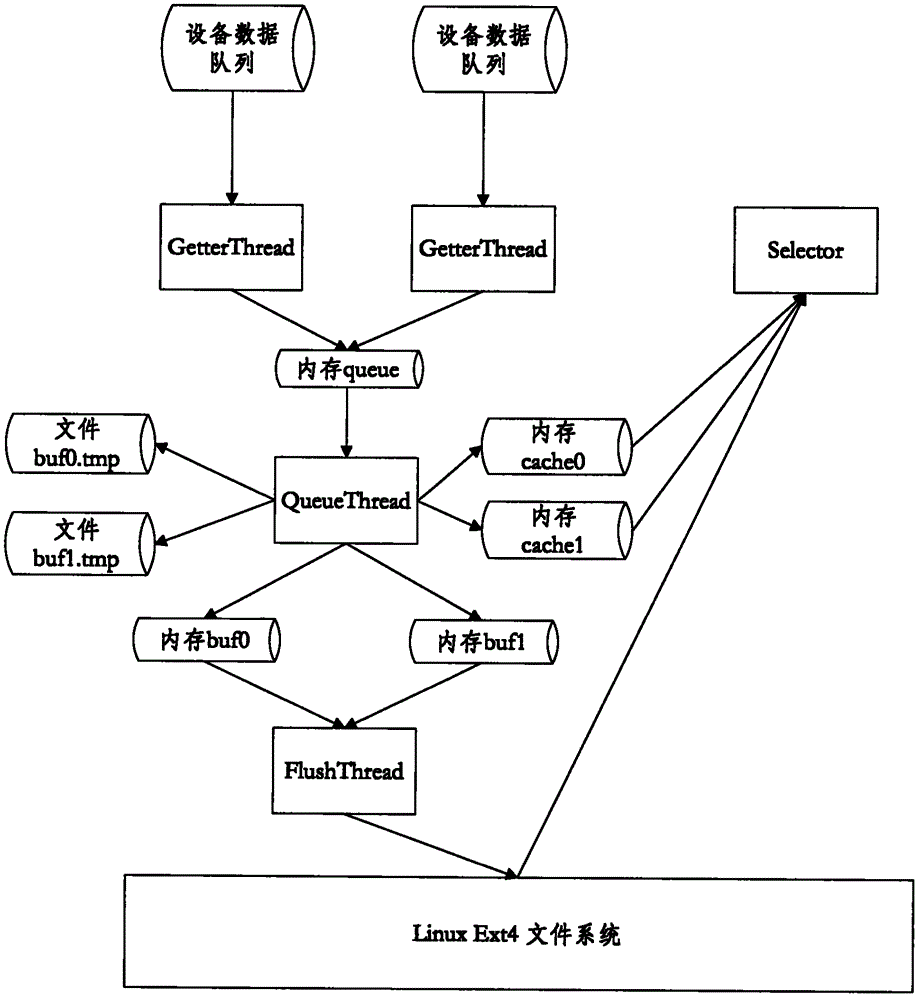
[0017] (1) In the file system of the server, directories are established according to time periods, and each directory contains many The device data file of the .data command, each device data file stores all the data records of the corresponding device id in the specified time period;
[0018] (2) After receiving the data uploaded by the device, the server will summarize all the data reported in the same time period into a directory named after the time period according to the data reporting time period, and then according to the device identification (id) one or more The reported data of the device is summarized into the file associated with the device identifier under the directory named after the time period;
[0019] (3) ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com