

Modeling approach and modeling system of acoustic model used in speech recognition
A technology of acoustic model and modeling method, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as low modeling accuracy and poor speech recognition effect, and achieve the effect of improving modeling accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0016] The technical solutions of the embodiments of the present invention will be described in further detail below with reference to the drawings and embodiments.
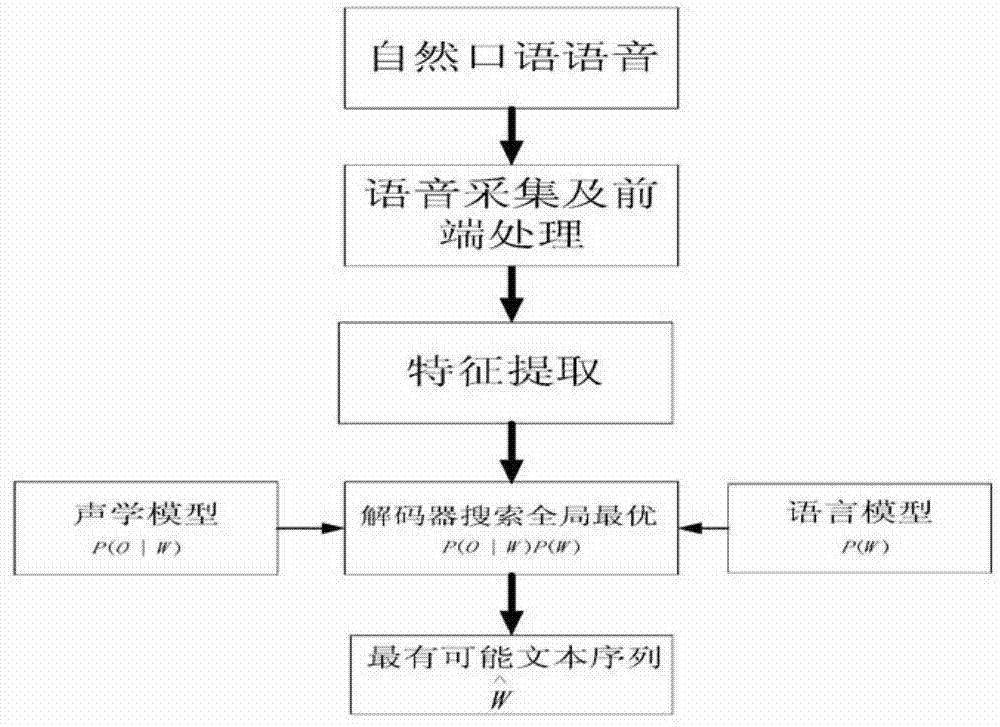
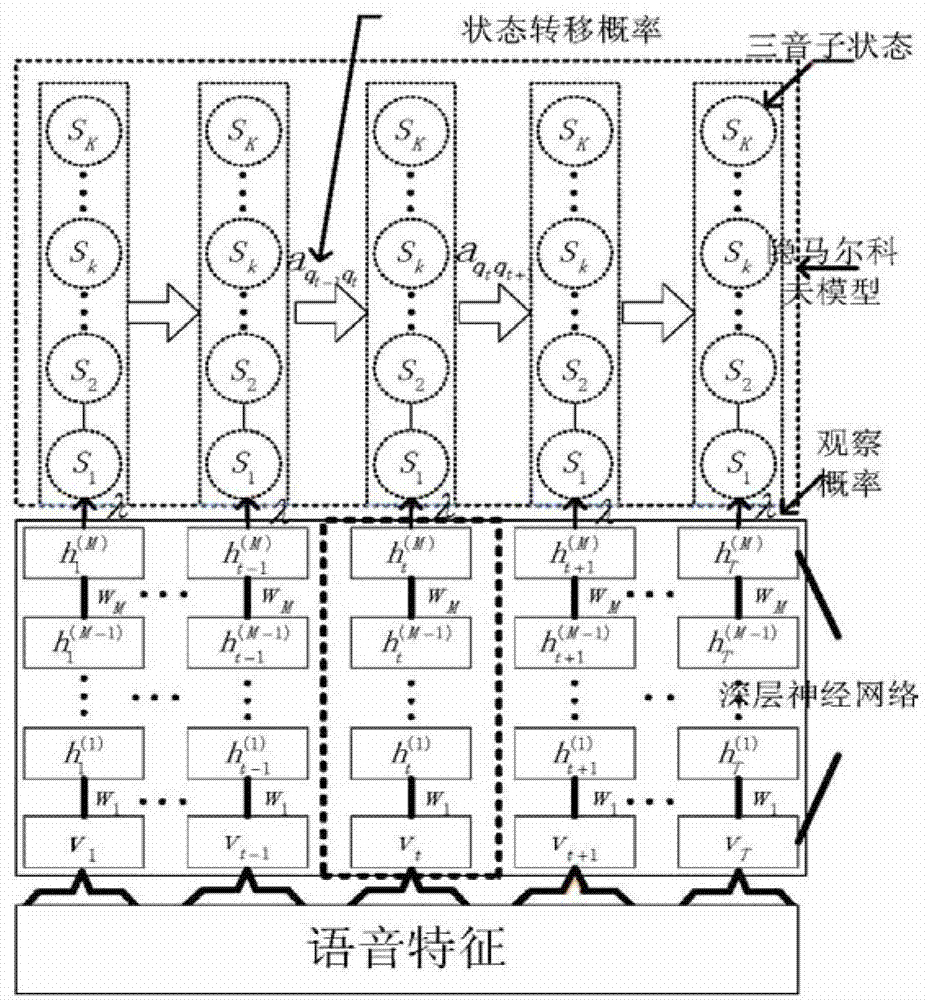
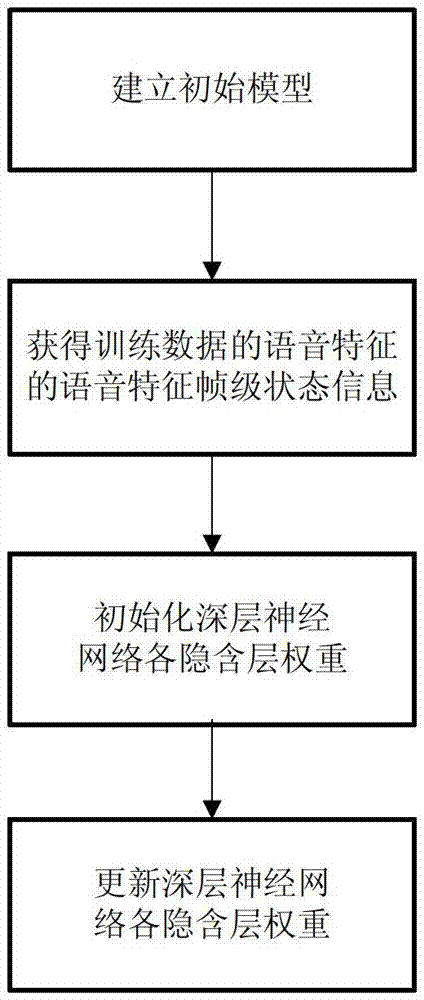
[0017] Considering that the mixed Gaussian model needs to make inappropriate assumptions about speech features and their probability distributions, the embodiment of the present invention uses a context-dependent deep neural network instead of the mixed Gaussian model for acoustic model modeling. The deep neural network includes a plurality of hidden layers, and its modeling unit is a context-dependent triphone state clustered by a phoneme decision tree. The basic block diagram of the whole system is as follows figure 2 shown.
[0018] The minimum cross-entropy criterion is used as the objective function during deep neural network training. Because it has multiple hidden layers, its error function has many local extremums, which makes it easy for the deep neural network to fall into local extremums during the t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More