

GPU thread scheduling optimization method
A scheduling method and thread technology, applied in the field of GPU thread scheduling, can solve problems such as damage locality, unbalanced warp progress, idleness, etc., and achieve the effect of improving utilization and avoiding pauses.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0030] The present invention is a GPU thread scheduling method, comprising the following processing steps:
[0031] Step 1: Architecture
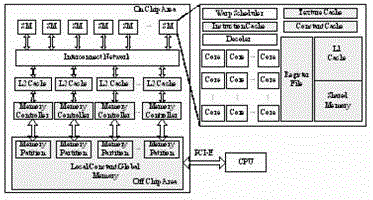
[0032] (A) The GPU architecture mentioned in this article refers to the CUDA structure.
[0033] (B) It contains multiple SMs (streaming multiprocessors) inside, and each SM contains multiple CUDA cores.
[0034] (C) Each CUDA core has a computational unit FU.
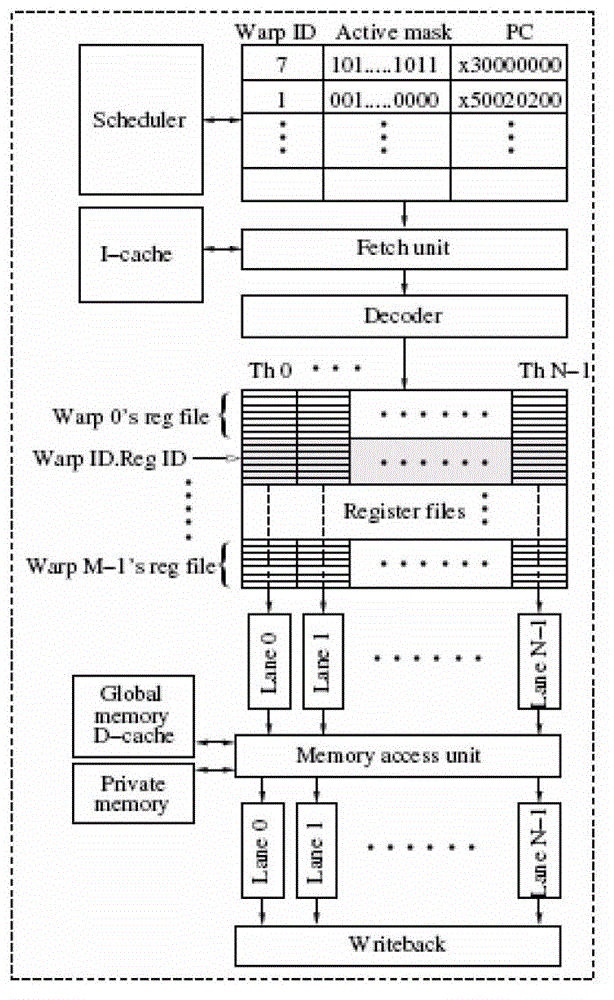
[0035] (D) A warp contains 32 threads, and the threads in the same warp execute the same instruction and process different data.
[0036] Step 2: Thread Block
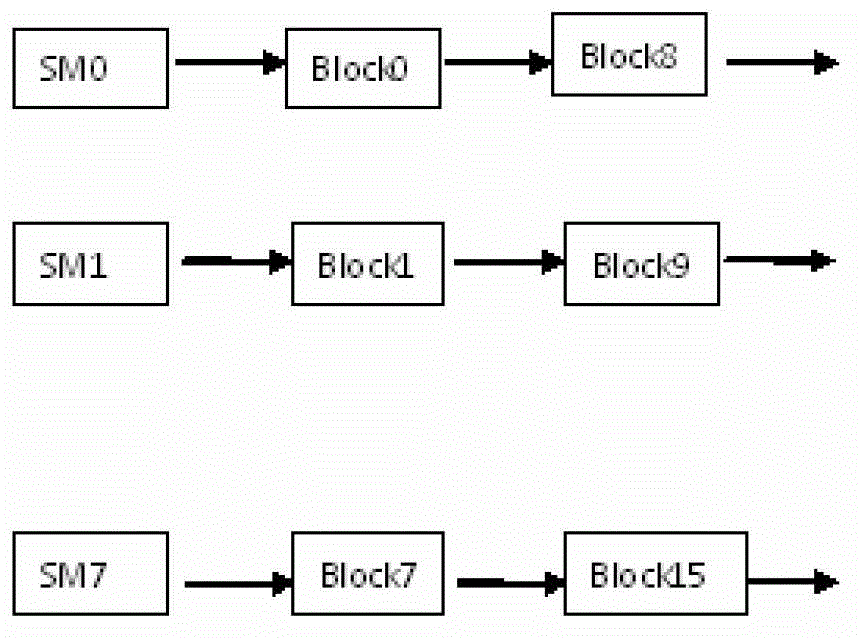
[0037] (A) A kernel corresponds to a thread grid, which is the general term for all the threads generated by the corresponding kernel, and the dimension of the grid is specified by the programmer during programming.
[0038] (B) The thread grid contains multiple blocks, and the dimension of the block is specified by the programmer. Thread blocks are numbered starting from 0.
[0039] (C) The thread block is mapped to t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More