

Data backup method of distributed file system
A distributed file and data backup technology, which is applied in the direction of data error detection, electrical digital data processing, special data processing applications, etc., can solve the problem of heavy network load, bandwidth occupation, and long time-consuming data backup, etc. problems, to achieve the effect of reducing execution time and reducing data transmission
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
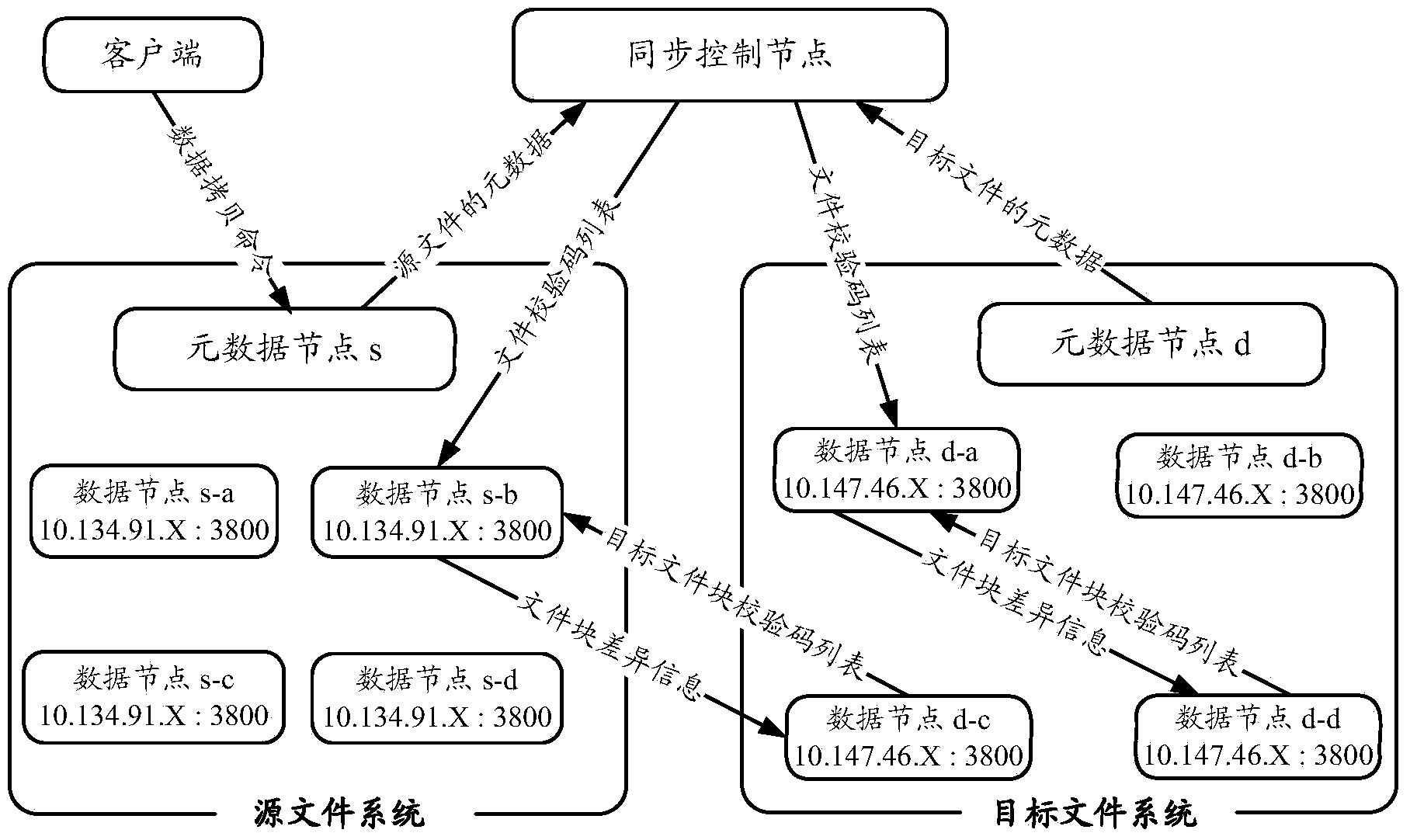
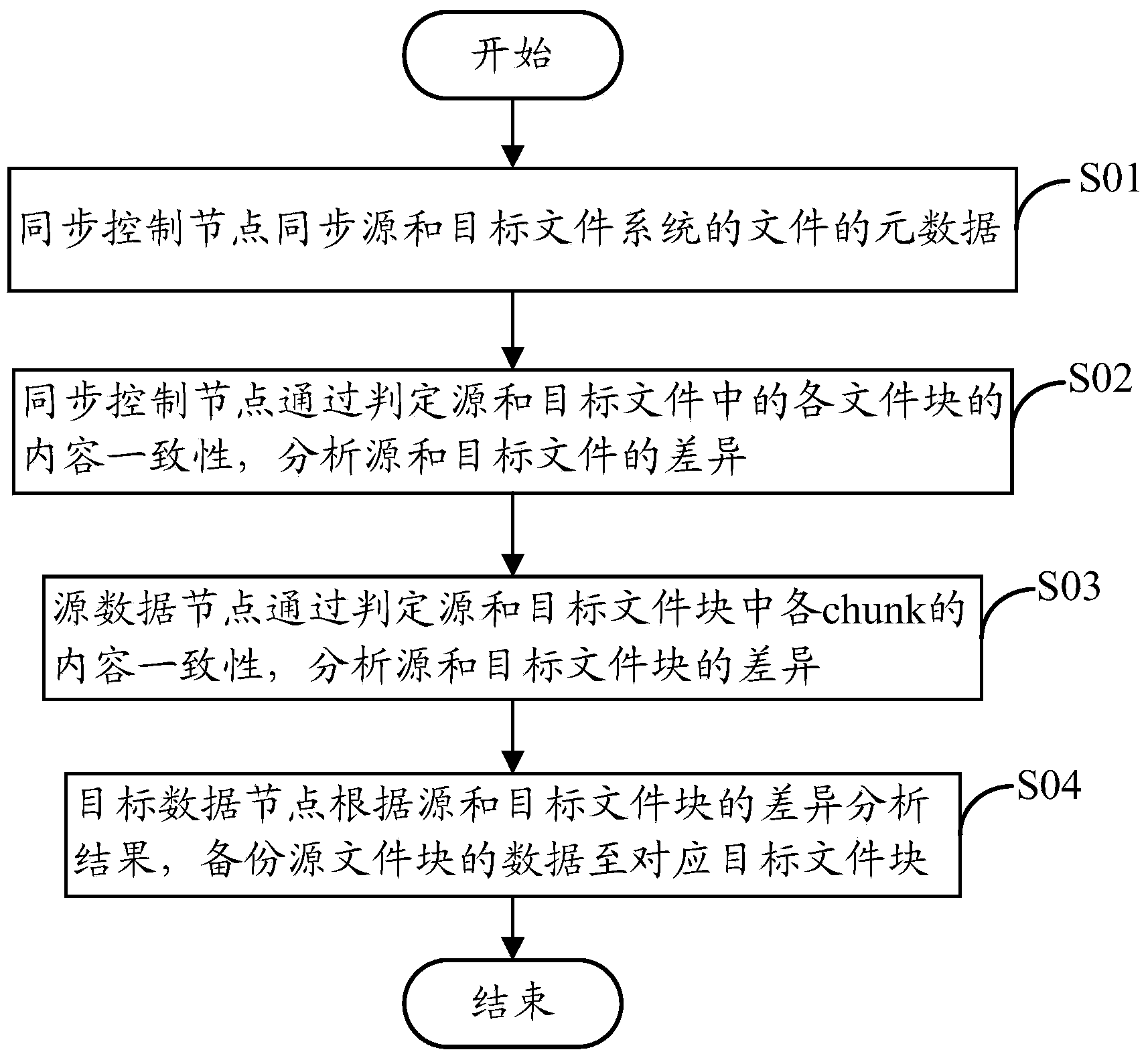
[0027] Before describing the technical solutions of the present invention in conjunction with specific implementation methods, a brief introduction is first made to the related concepts of the HDFS file system. The HDFS file system is a master-slave structure, including a metadata node (Name Node, metadata node or name node) and several data nodes (Data Node), allowing users to store data in the form of files, each file is divided into several ordered File blocks or data blocks (usually 64MB in size), stored on a set of data nodes. The metadata node serves as the master server to provide metadata services and client access operations on files, etc., and the data node is used to manage stored data. In addition, the data backup method of the present invention introduces the concept of chunk in order to speed up the file transfer speed during the data backup process. The chunk refers to a basic unit that divides a file block into a number of file blocks (256 by default), called ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More