

Big data clustering method based on decomposition and composition
A clustering method and big data technology, applied in database model, relational database, electronic digital data processing and other directions, can solve the problems of high dimension, difficult internal model of big data, and large amount of big data.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

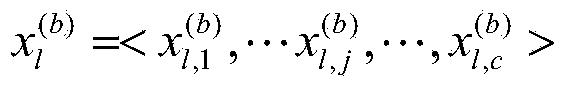
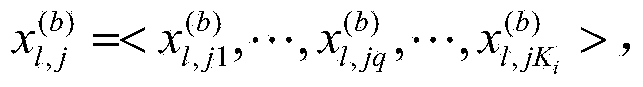
Examples
Embodiment Construction
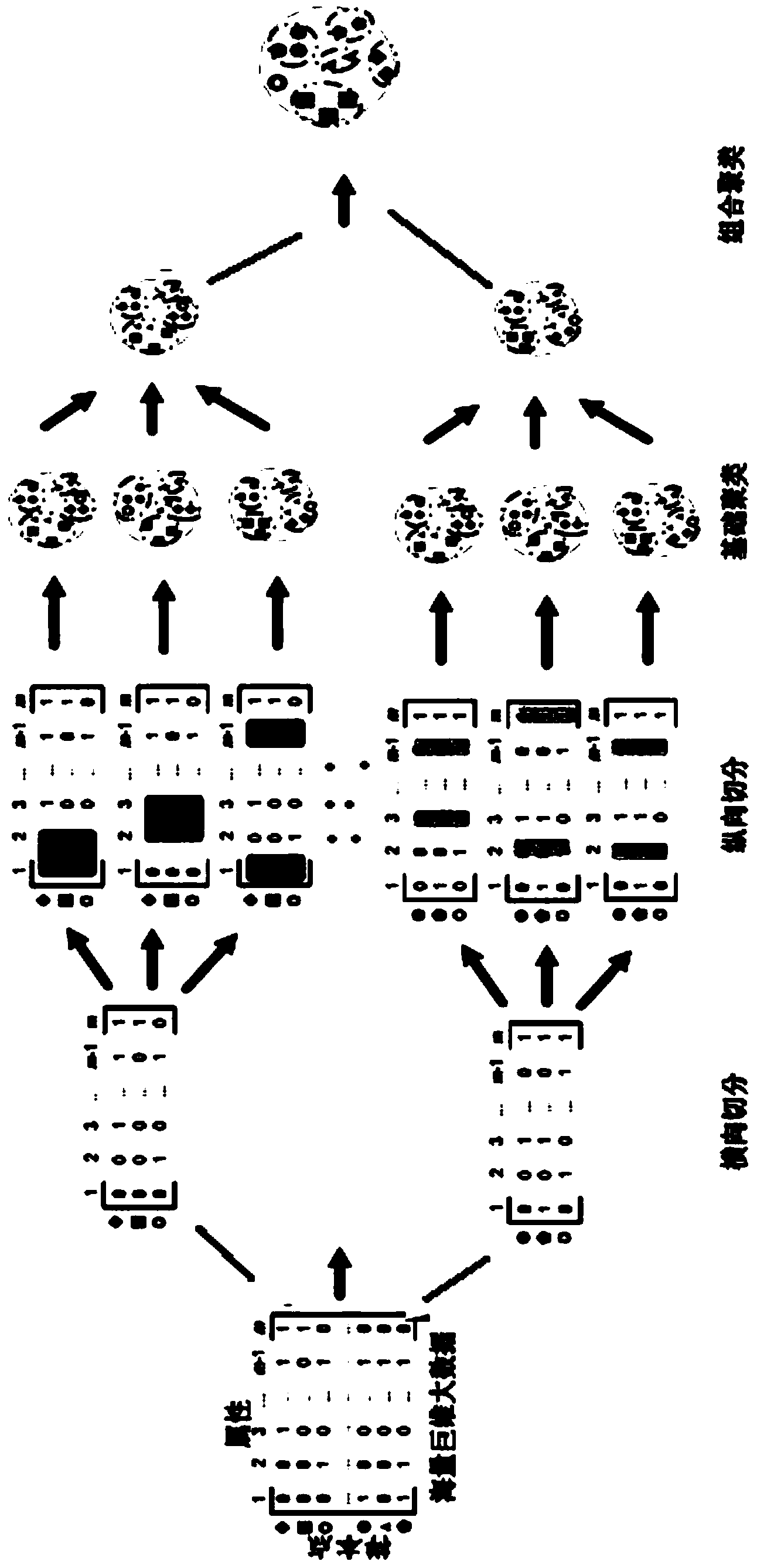
[0049] A decomposition-combination clustering method for big data. Firstly, the big data is divided horizontally and vertically; then, the category label of each data subset is obtained, and then the category label of the entire data set is obtained by using the combination clustering method. The specific implementation steps are as follows:
[0050] 1) Horizontal segmentation. Use random sampling to horizontally split the big data, that is, randomly draw 10% of the sample size to obtain the data subset D i , repeated sampling with replacement r = 100 times, so that the full set of 100 data subsets is D.
[0051] 2) Vertical segmentation. Using random sampling, for each data subset D i Carry out vertical segmentation, that is, randomly extract 10% of the attributes to obtain the data subset D ij , repeated sampling with replacement c=100 times, making 100 data subsets D ij The complete set is D i .
[0052] 3) Obtain category labels for subsets of data. Use K-means for...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More