

Acoustic model training method and device
An acoustic model and training method technology, applied in speech analysis, speech recognition, instruments, etc., can solve problems such as the inability to achieve good performance of SGD algorithm, second-order optimization without first-order optimization, etc., to reduce deviation, improve performance, and shorten time. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
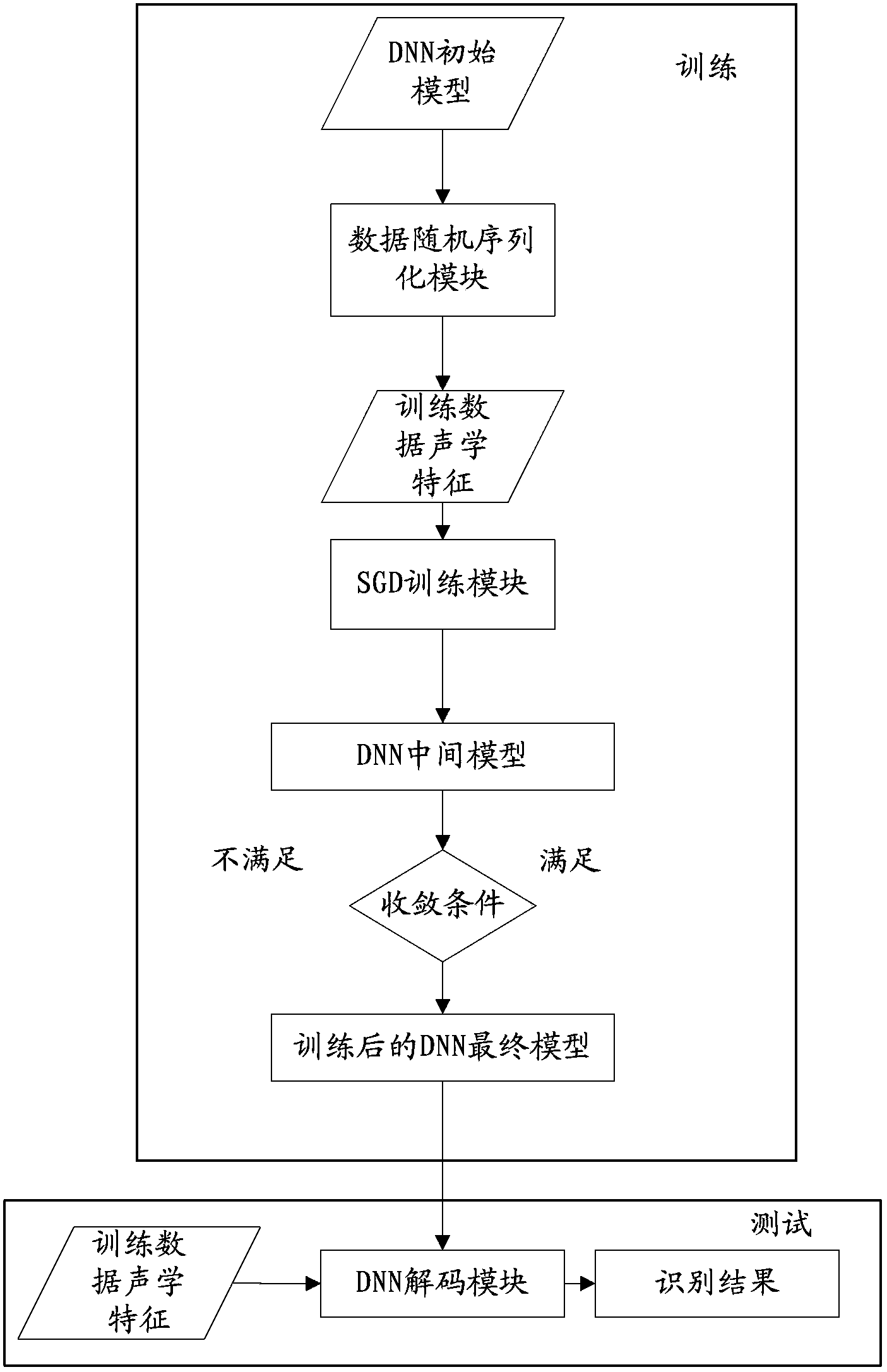
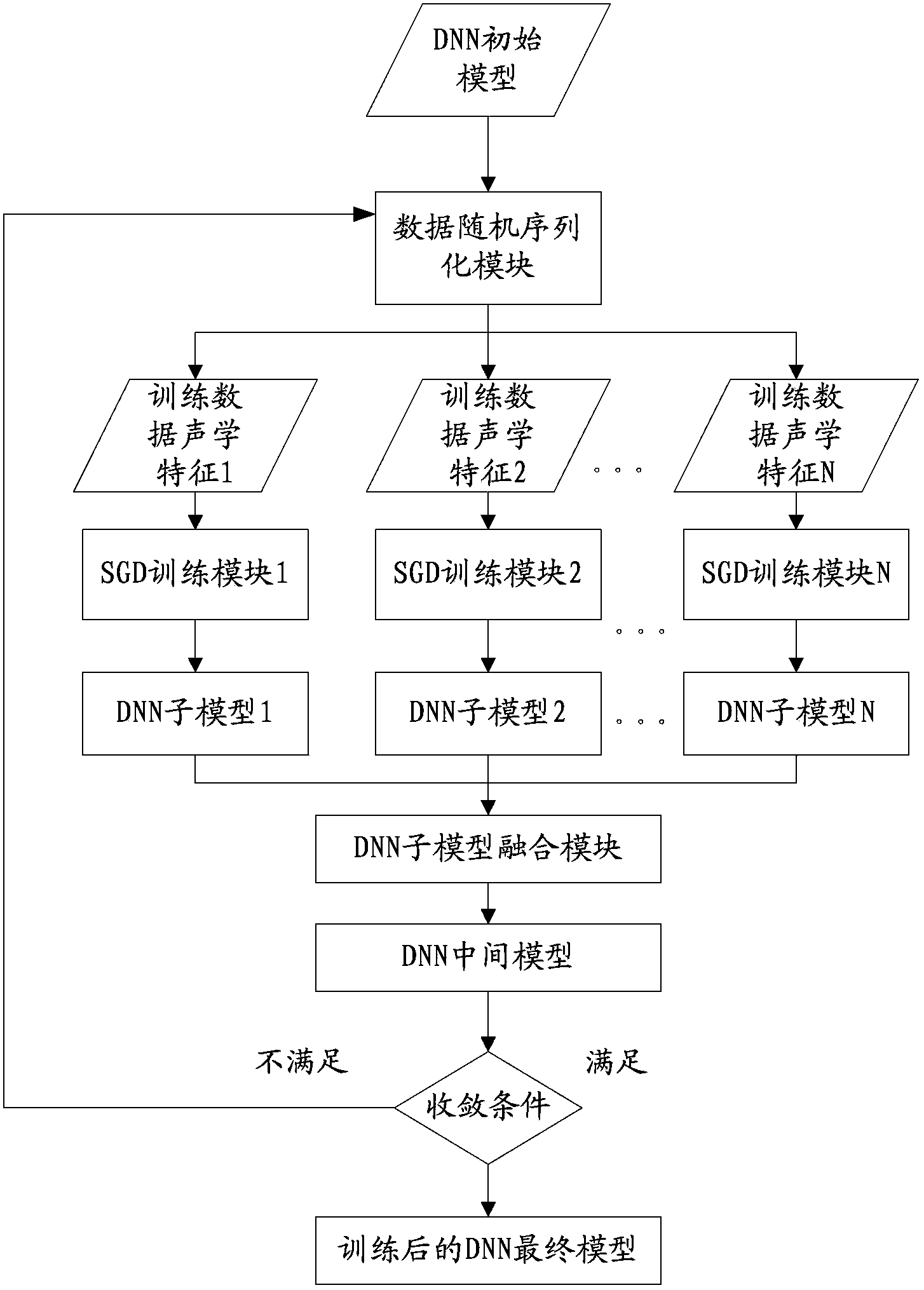
[0025] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0026] The embodiments of the present invention focus on the training of the acoustic model, which is the core step of the speech recognition technology.
[0027] Speech recognition is a serialized classification problem, the purpose of which is to convert a series of collected speech signals into a series of text outputs. Since the voice signals are temporally correlated, that is, the voice data at a certain moment is related to the voice data at several previous moments. In order to simulate the mechanism of speech data generation, the Markov model was introduced into the field of speech recognition. In order to further simplify the complexity of the model, each current state of the Markov model is only related to the state at the previous moment.
[0028] For...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More