

Text big data-oriented Chinese word segmentation method
A Chinese word segmentation and big data technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., to achieve the effect of improving throughput, improving accuracy, and reducing word segmentation time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

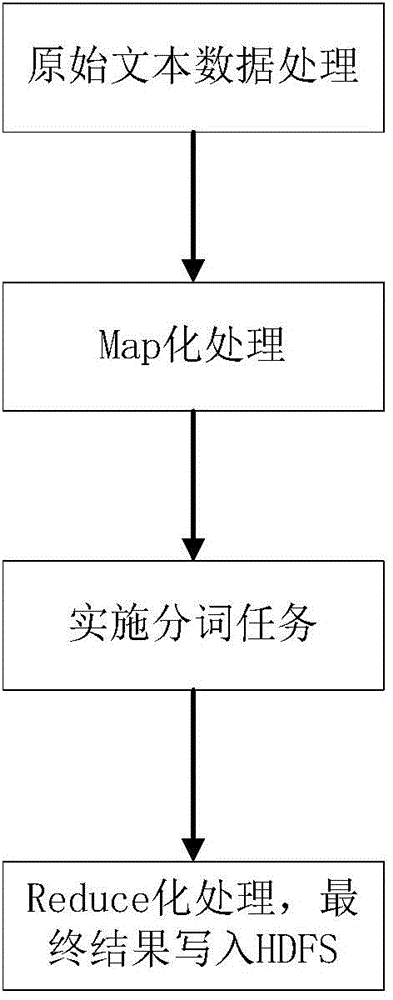
Examples
Embodiment Construction
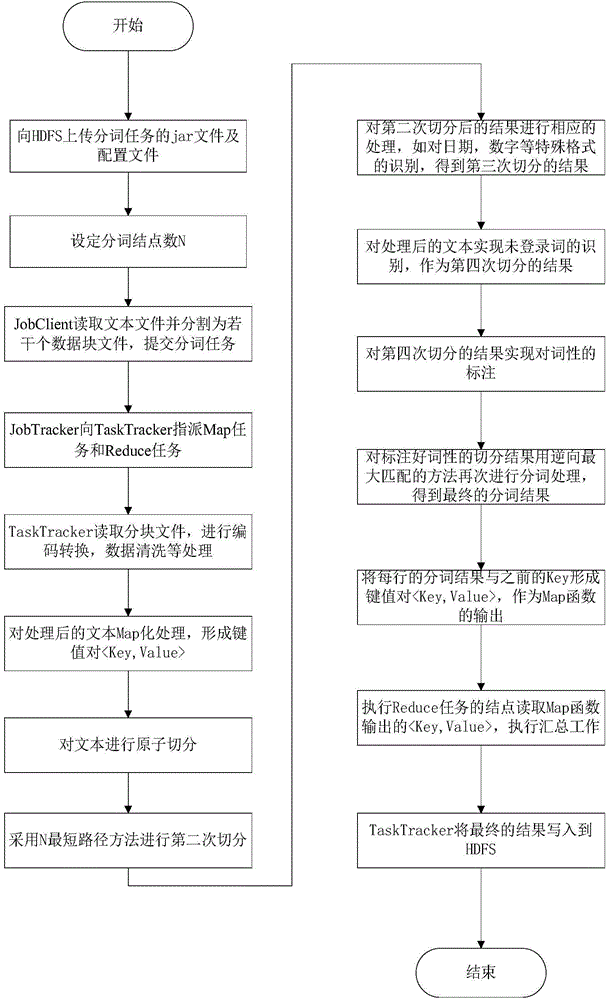
[0051] Below at first technical terms of the present invention are explained and illustrated:
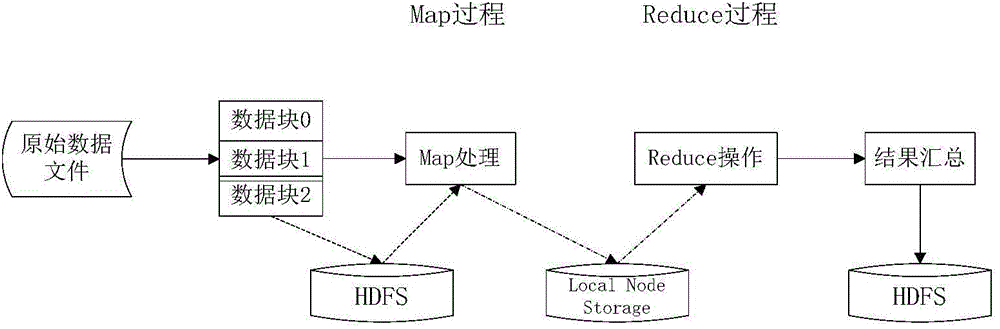
[0052] MapReduce computing model: MapReduce is a general software framework proposed by Google to implement distributed parallel computing tasks. It simplifies the parallel software programming model on super-large clusters composed of ordinary computers, and can be used for parallel computing of large-scale data sets.
[0053] Hadoop Distributed File System: Hadoop is a distributed system infrastructure developed by the Apache Foundation. The core design of the Hadoop framework is: HDFS (Hadoop Distributed File System) and MapReduce. HDFS provides storage for massive data, and MapReduce provides calculation for massive data. In the Hadoop distributed file system, there are mainly three roles: JobClient, JobTracker, and TaskTracker. JobClient is used to submit tasks; JobTracker is used to monitor the running status of Task and perform corresponding scheduling; TaskTracker actively...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More