Adaptive indexing method and device
An adaptive and indexing technology, applied in the database field, can solve the problems of slow database convergence, resource consumption of query processing, low query efficiency, etc., and achieve the effect of reducing resource consumption, improving convergence speed, and increasing convergence speed.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
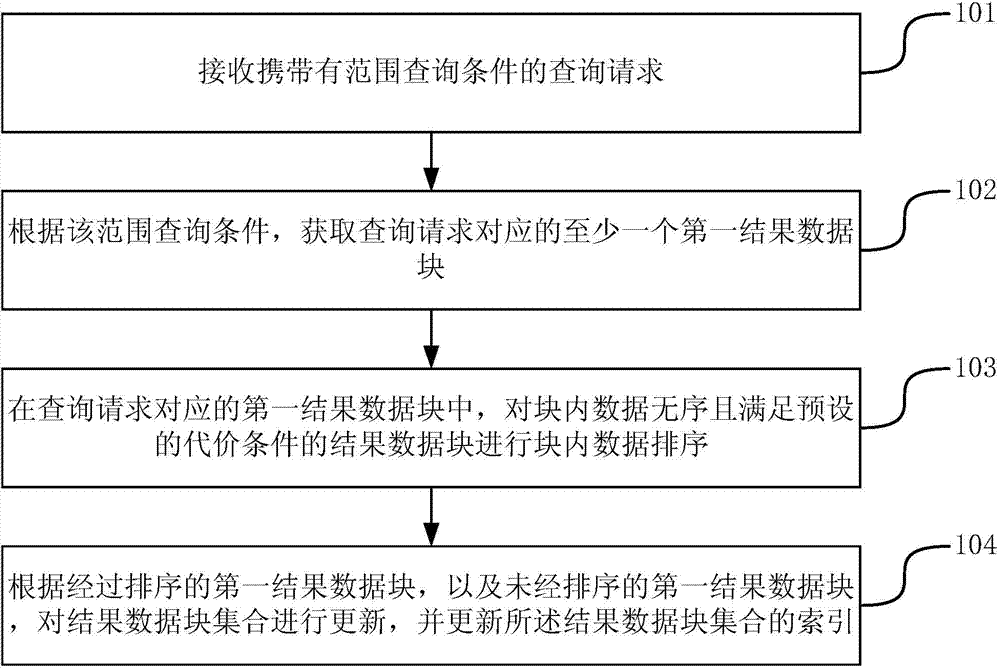
[0031] The embodiment of the present invention provides a method for self-adaptive indexing, and the result data block set of the database is indexed, such as figure 1 As shown, the processing flow of the method may include the following steps:
[0032] Step 101, receiving a query request carrying range query conditions.
[0033] Step 102, according to the range query condition, at least one first result data block corresponding to the query request is obtained.
[0034] Step 103 , in the first result data block corresponding to the query request, perform intra-block data sorting on the result data blocks whose data in the block is out of order and satisfy the preset cost condition.
[0035] Step 104: Update the result data block set according to the sorted first result data block and the unsorted first result data block, and update the index of the result data block set.
[0036] In the embodiment of the invention, by setting the cost condition, only the result data blocks ...
Embodiment 2
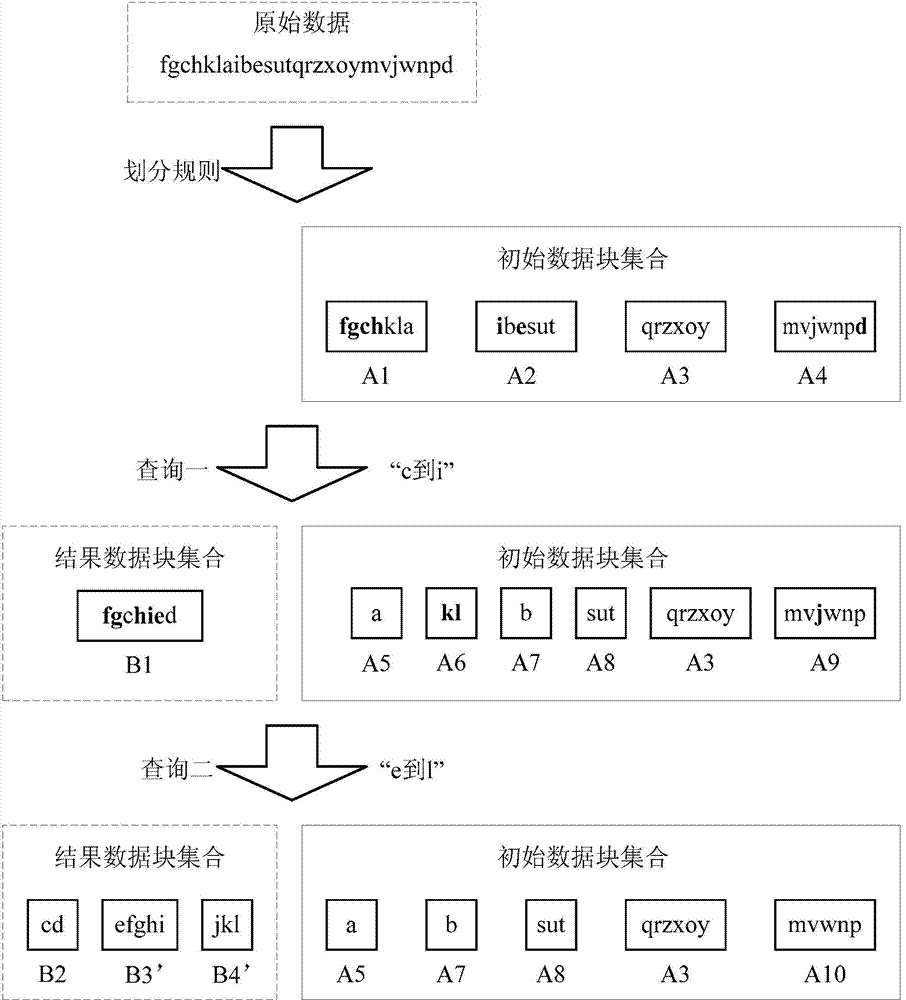
[0038] The embodiment of the present invention provides a method for self-adaptive indexing. The result data block set of the database has an index, and the data range of each result data block in the result data block set can be recorded in the index. Preferably, an AVL tree can be used as the result The index of the data block collection, each leaf node of the AVL tree corresponds to record the data range of each result data block. The execution subject of the method may be a server or a terminal device with a database established therein.
[0039] The following will be combined with specific implementation methods to figure 1The processing flow shown is described in detail, and the content can be as follows:
[0040] Step 101, receiving a query request carrying range query conditions.
[0041] Wherein, the range query condition is a query condition for querying data within a certain data range, for example, the range query condition may be greater than a and less than b, ...
Embodiment 3
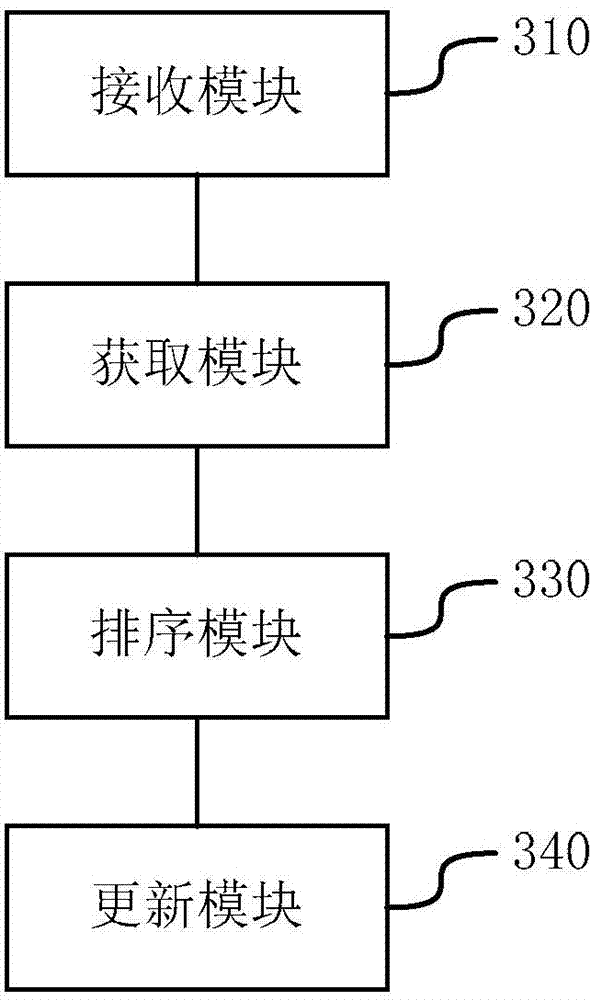
[0134] Based on the same technical idea, the embodiment of the present invention also provides an adaptive indexing device, and the result data block set of the database is indexed, such as image 3 As shown, the device includes:
[0135] A receiving module 310, configured to receive a query request carrying a range query condition;
[0136] An acquisition module 320, configured to acquire at least one first result data block corresponding to the query request according to the range query condition;
[0137] A sorting module 330, configured to, in the first result data block corresponding to the query request, perform intra-block data sorting on the result data blocks whose data in the block is out of order and satisfy a preset cost condition;
[0138] The update module 340 is configured to update the result data block set according to the sorted first result data blocks and the unsorted first result data blocks, and update the index of the result data block set.
[0139] Pr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com