

Hadoop job scheduling method based on genetic algorithm
A job scheduling and genetic algorithm technology, applied in the field of Hadoop job scheduling based on genetic algorithm, can solve the problem of inability to take into account job fairness and job execution efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

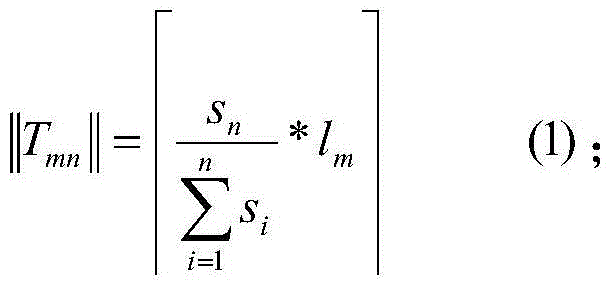
Examples
Embodiment Construction
[0056] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
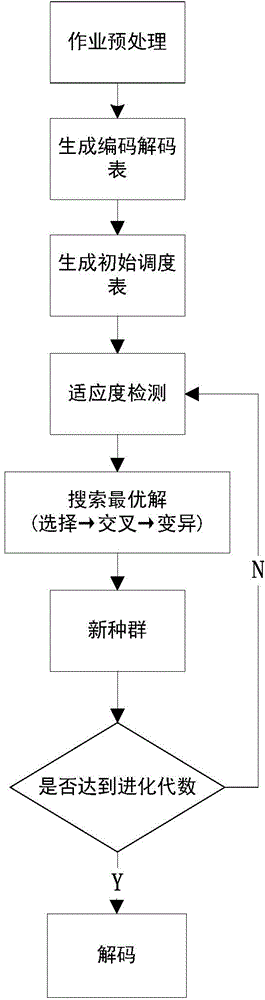
[0057] see figure 1 , the Hadoop job scheduling method based on genetic algorithm of the present invention, comprises the following steps:
[0058] Step 1: Job Preprocessing
[0059] At the JobTracker node, firstly summarize the jobs waiting to be scheduled and the TaskTracker nodes in the cluster. For each job in the job queue, count the number of fragments of each job l m and the maximum number of TaskTrackers it can be scheduled b m ,As shown in Table 1:
[0060] Table 1
[0061] job
split
TaskTracker
job 1
l 1
b 1
job 2
l 2
b 2
……
……
……
job m
l m
b m
[0062] Among them, Job 1 、Job 2 ... Job m The order of jobs is first-come-first-served.
[0063] For each TaskTracker node, read the maximum number of parallel slots s in the corresponding con...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More