

Method for storing and processing small log type files in Hadoop distributed file system
A technology of distributed files and hadoop clusters, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of complex and opaque analysis and processing of small files, and achieve the effect of solving memory load problems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0025] The computers in the cluster are divided into NameNode and DataNode according to their functions. When a client accesses a specific file in HDFS, it first obtains the Metadata information of the file from the NameNode, and then establishes a connection with the DataNode to obtain the read and write file data. The operation process of client accessing files is encapsulated in the form of client library, and the process of communicating with NameNode and DataNode is transparent to the client.
[0026] Small log files are merged according to the nearest physical path. Specifically, small log files in the same directory (excluding subdirectories) are merged into one file, which is called MergeFile. The Metadata of small log files are sequentially stored in a file, which is called MergeIndex. The merged file and the merged file index are located in the original HDFS directory and are named with the reserved file name. MergeFile supports append, modify, and delete operations...
Embodiment 2
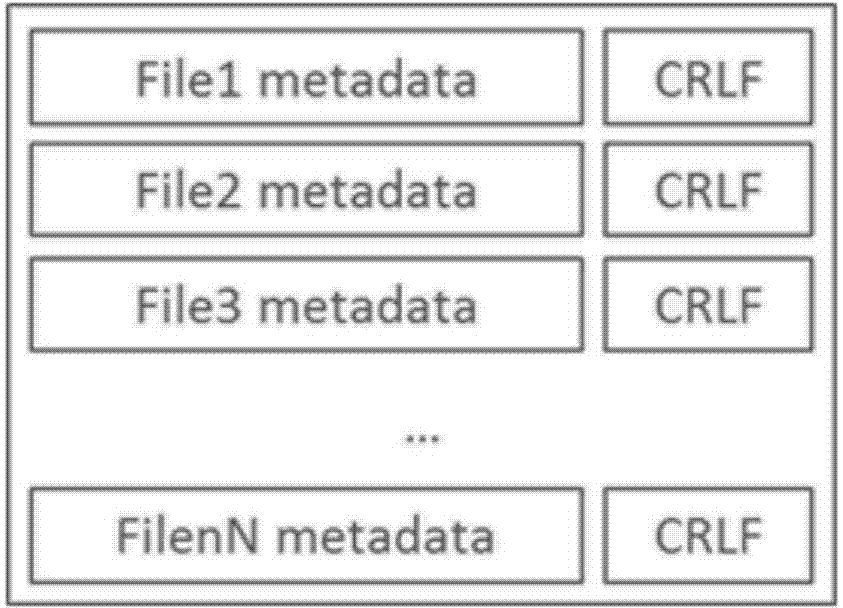
[0028]On the basis of Embodiment 1, this embodiment performs special processing on log-type small files. Log-type small files are a kind of derivation of HDFS files at the interface level. When creating a file, the client specifies whether the created file is log-type or not. small files. There is a unique pair of MergeIndex file and MergeFile file in the parent directory of each small log file. The file merge operation is triggered when the write operation of the log-type small file ends, the file content is appended to MergeFile, and the file Metadata is appended to MergeIndex. The MergeFile structure is as follows figure 1 As shown, multiple small files are tightly connected and stored in MergeFile, and the data is not compressed. The MergeIndex structure is as follows figure 2 As shown, each file Metadata record occupies one line (the end of the line adopts "carriage return line feed character CRLF").
[0029] The detailed writing process of log-type small files is as...
Embodiment 3
[0039] On the basis of Embodiment 2, the operation process of the client in this example to read and write files is as follows:
[0040] (1) According to the file path specified by the client, the client library communicates with the NameNode to confirm whether the file corresponding to the file path exists. If the file exists, the file is an ordinary HDFS file, and no special processing is performed according to the HDFS original read and write process; if the file does not exist, the file may be a small journal-type file, and then go to step (2).
[0041] (2) The client library reads the MergeIndex under the parent directory of the specified path, and traverses the file items from back to front to find the specified file. If the search fails, the specified path does not exist, and an error is returned; if the search is successful, the file is a log-type small file, and the read and write requests are correspondingly transferred to steps (3) and (4).
[0042] (3) According t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More