

A mapreduce parallelized big data text classification method
A text classification and classification method technology, applied in the computer field, can solve the problems of poor classification performance and low discrimination, and achieve the effect of improving discrimination and classification performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] The present invention will be further described below in conjunction with the accompanying drawings.
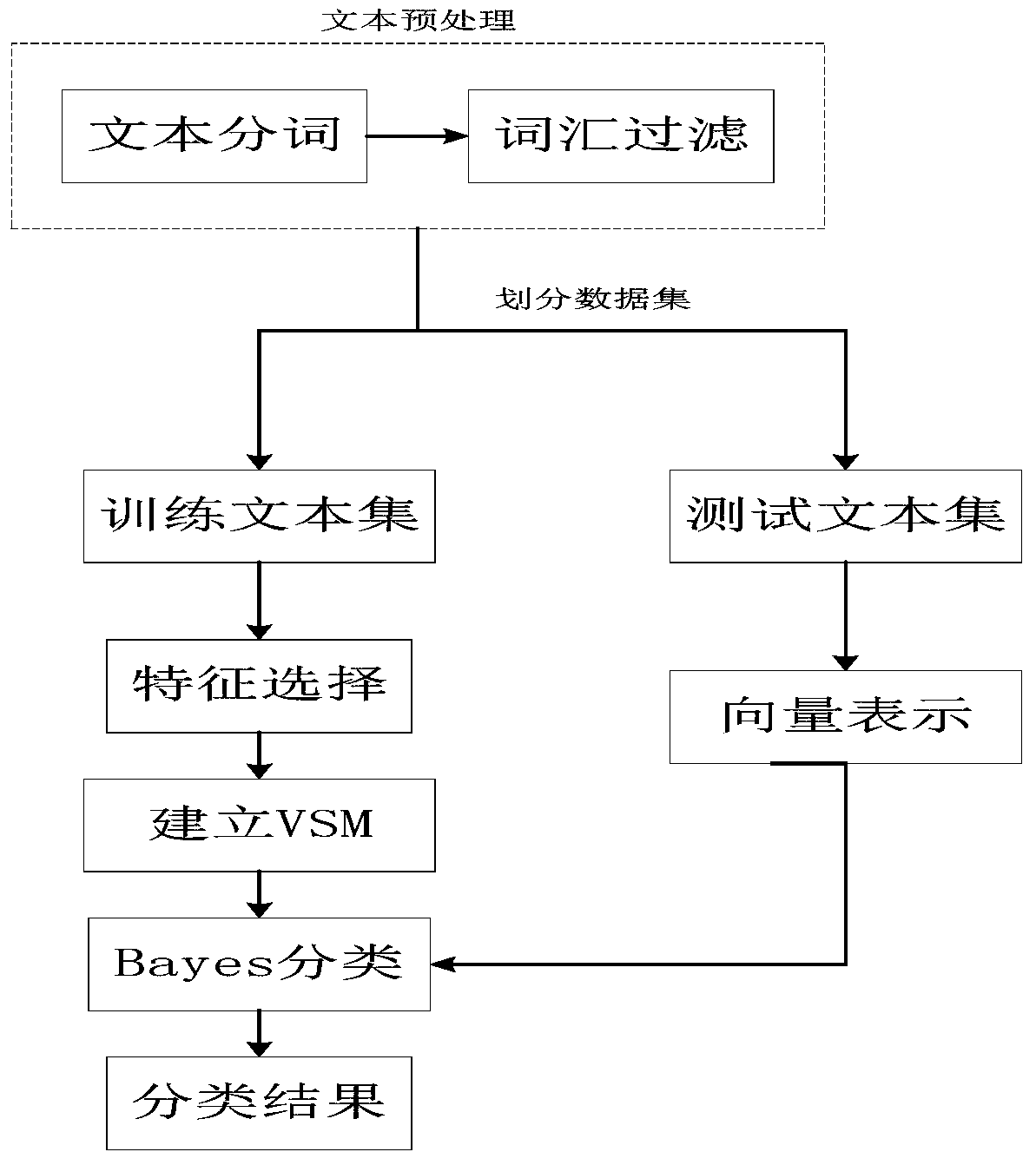
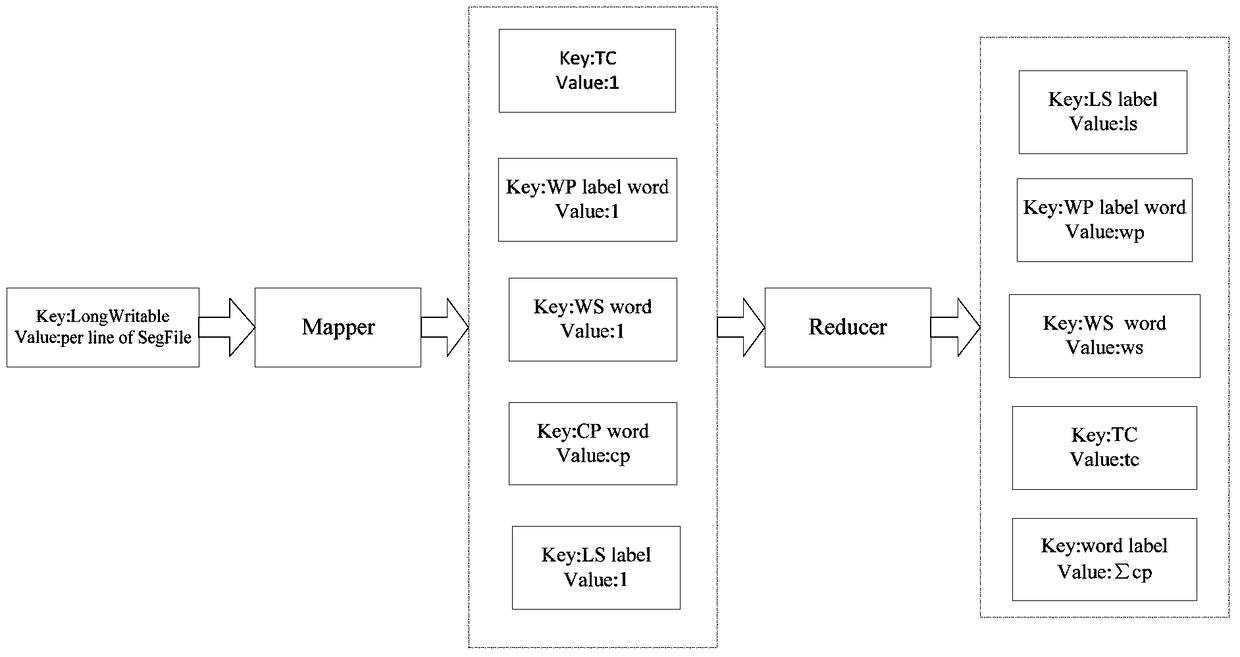
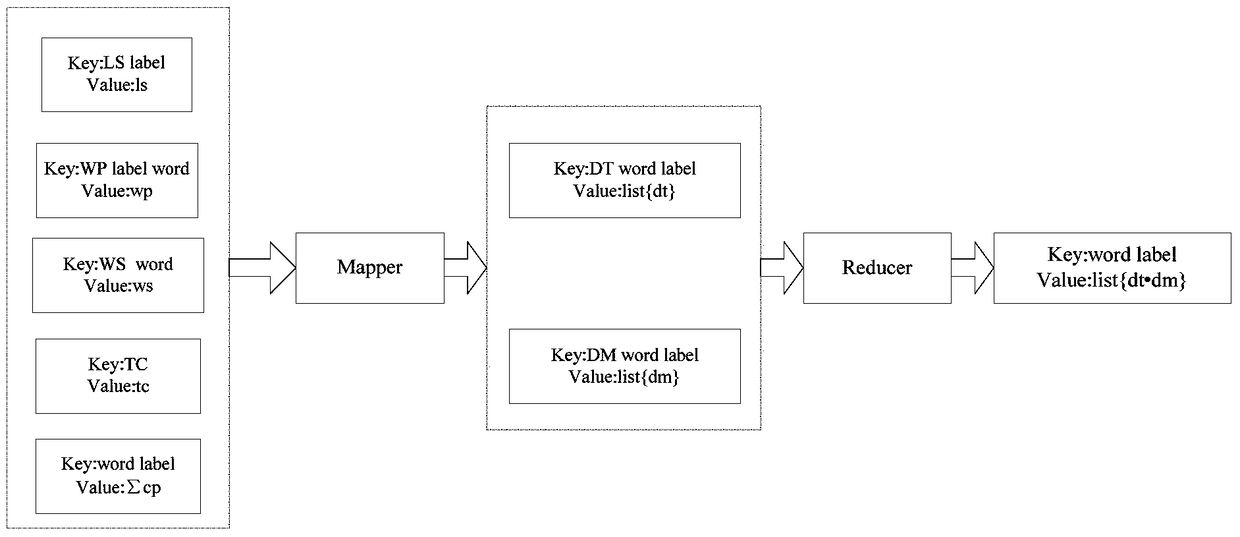
[0029] refer to Figure 1 ~ Figure 4 , a MapReduce parallelized big data text classification method, according to the Bayesian algorithm and the characteristics of the MapReduce programming model, each step of text classification is realized in parallel under the Hadoop platform. It includes four steps of data preprocessing, feature extraction, text vector representation and classification of text classification, specifically including the following processes:
[0030] The first step: data preprocessing. It includes two processes of word segmentation and removal of stop words;
[0031] The second step: feature extraction. Process the training data set and filter out the feature items (words) with the strongest distinguishing ability and the most representative;
[0032] The third step: the implementation of the Bayesian algorithm. Classify the test data set using ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More