

Rapid statistics task generation system and method suitable for big data
A big data and task technology, applied in the field of data statistics, can solve the problems of low reuse and development efficiency, complex debugging process, inability to adapt to the development process of big data, etc., and achieve the effect of improving development efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment
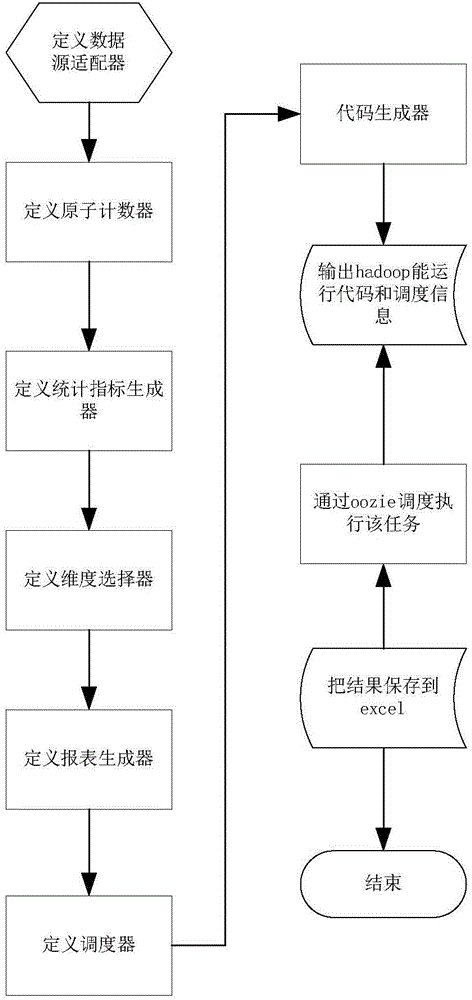
[0096] refer to figure 1 , Statistical task: Calculate the number of successful SMS sending, the number of SMS sending failures, the total number of SMS sending, the success rate of SMS sending, and the failure rate of SMS sending for each city in Guangdong Province every day. This is achieved through the following steps:
[0097] (1) Define the data source adapter, first define the input SMS data source attributes, such as the table name bssap, the field cdr_type, and the type is int, where cdr_type=10 means sending SMS, cdr_result=1 means sending SMS successfully, and other means failure; define The field name is city_name, and the type is string, indicating the name of the city, etc.
[0098]If there is a data source adapter corresponding to the SMS data source attribute in the data source adapter warehouse, it will be called directly from the library. If not, a new data source adapter will be created and saved in the data source adapter warehouse.
[0099] (2) Define ato...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More