

Blank region processing method and system for electronic document
A blank area and electronic document technology, applied in the direction of electronic digital data processing, special data processing applications, natural language data processing, etc., can solve the problem that redundant blank areas cannot be reduced, achieve the purpose of retaining typesetting interval information, and reducing page turning operations , to ensure the effect of compact
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
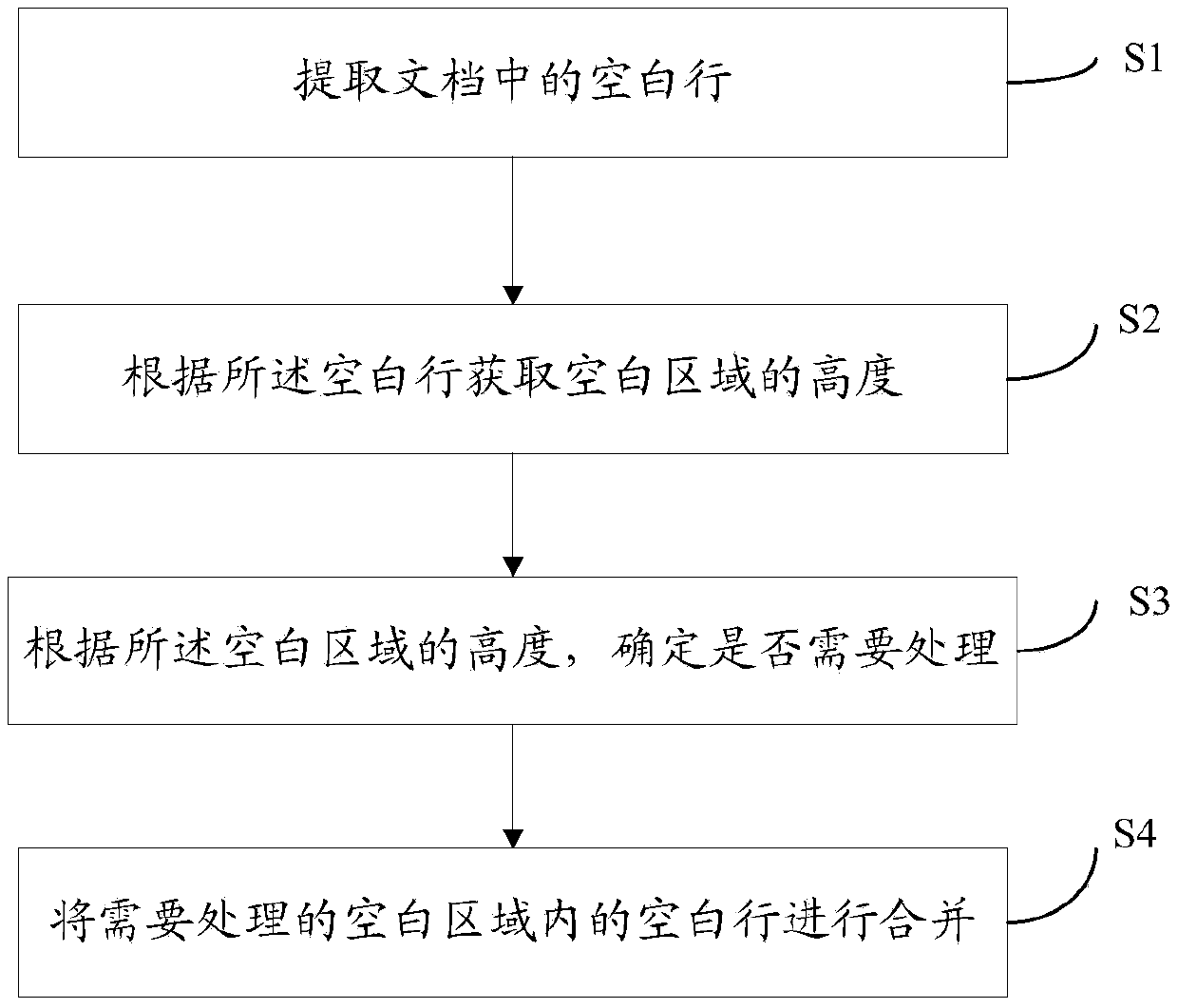
[0053] This embodiment provides a method for processing a blank area in an electronic document, including the following process:
[0054] S1: Extract blank lines in the document. Here, it can be obtained by parsing the document information and extracting its file attribute information. For example, a space or a carriage return in a file attribute can be regarded as a blank line.
[0055] As an optimized implementation solution in this embodiment, in this step, the chapter information of the entire document can be obtained first, and then the blank line information of each chapter file can be obtained sequentially. The specific steps are as follows:
[0056] S11. Obtain the chapter file and the catalog file of the document, which can be obtained by parsing the attribute information of the document.
[0057] S12. Determine the traversal order of the chapter files according to the directory file.
[0058] S13. Detect the paragraph tags of each chapter file in turn, and obtain t...
Embodiment 2
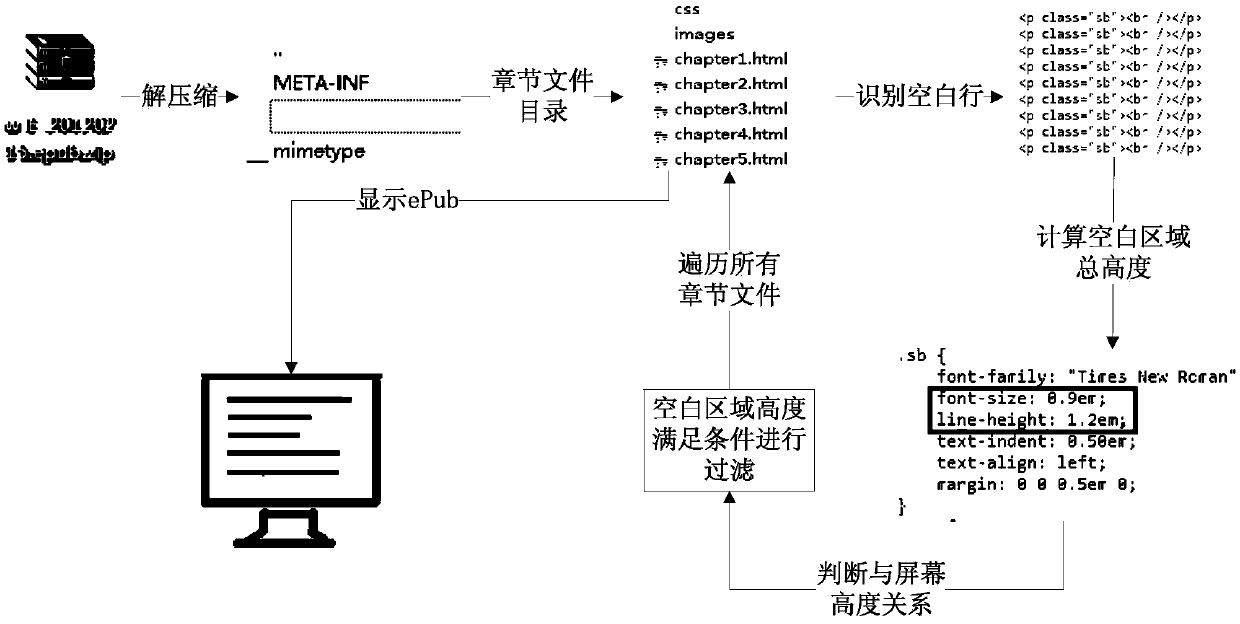
[0070] A method for processing blank areas in electronic documents is provided in this embodiment, which is to analyze documents in ePub format. The schematic diagram of the entire processing process is as follows figure 2 shown.
[0071] Consecutive empty paragraph tags may exist in text elements of html text in ePub documents The resulting white page area, if the white page area is large, will affect the user's reading experience.
[0072] The scheme in the present embodiment comprises concrete steps as follows:
[0073] 1. The inside of the ePub document is a zip package. First decompress it to get the directory (OPS or OEBPS) where the chapter files are located, and then determine the traversal order of the xhtml / html chapter files according to the order described in the directory file.
[0074] 2. Detect the html tags of all chapter files in turn, and judge the tags that may cause blank lines, such as paragraph tags Values are spaces, newlines, etc.
[0075]...
Embodiment 3
[0081] In this embodiment, a specific application example is given for processing the blank area in the ePub document. It is assumed that the height of the visible area of the target device is H, and the height of each row is h, and h is equal to the sum of the row height and the row spacing.
[0082] The first step is to decompress the ePub document, traverse the html / xhtml files corresponding to all chapters, and there are m chapters in total;
[0083] The second step, starting from the first chapter, traverse the html tags in the chapter file, set a blank line counter sum, and set the initial value to 0;
[0084] In the third step, in the chapter file, every time a continuous blank line is detected, the sum value is increased by 1, and if the next line of the blank line is not a blank line, then sum=0;
[0085] The fourth step, when sum*h>=H*p, replace the continuous sum line with a blank line, reset the sum to 0, and p is the proportional coefficient, set as re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More