

A Construction Method of Chinese Semantic Knowledge Base Based on Machine Translation
A semantic knowledge base and construction method technology, applied in the field of Chinese semantic knowledge base construction, can solve the problems of lack of Chinese semantic knowledge base, expensive manpower and time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

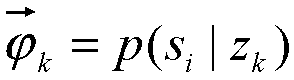
Examples
specific Embodiment approach 1
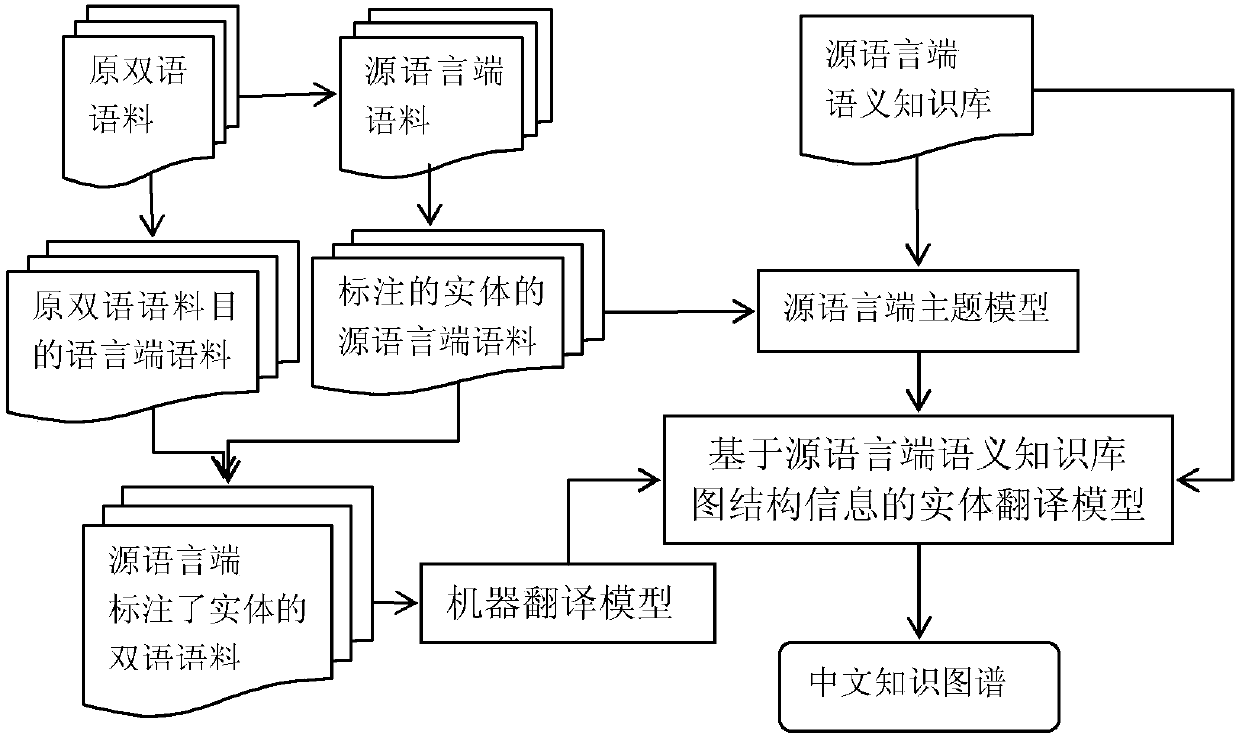
[0025] Specific embodiment 1: The method for constructing a Chinese semantic knowledge base based on machine translation in this embodiment is specifically prepared according to the following steps:
[0026] Based on the entities in the source language semantic knowledge base, the source language-side monolingual corpus is segmented and named entity recognition, and the machine translation model based on the source language-side semantic knowledge base graph structure information;
[0027] Step 1. Use the entities in the source language semantic knowledge base to identify the source language corpus in the original bilingual corpus to obtain the source language corpus labeled with the entity;
[0028] Step 2: Use the source language corpus with the entities obtained in Step 1 to construct a topic model, and calculate the topic distribution of the entity according to the topic model;
[0029] Step 3: The source language corpus with the entity annotated and the target language corpus with...
specific Embodiment approach 2
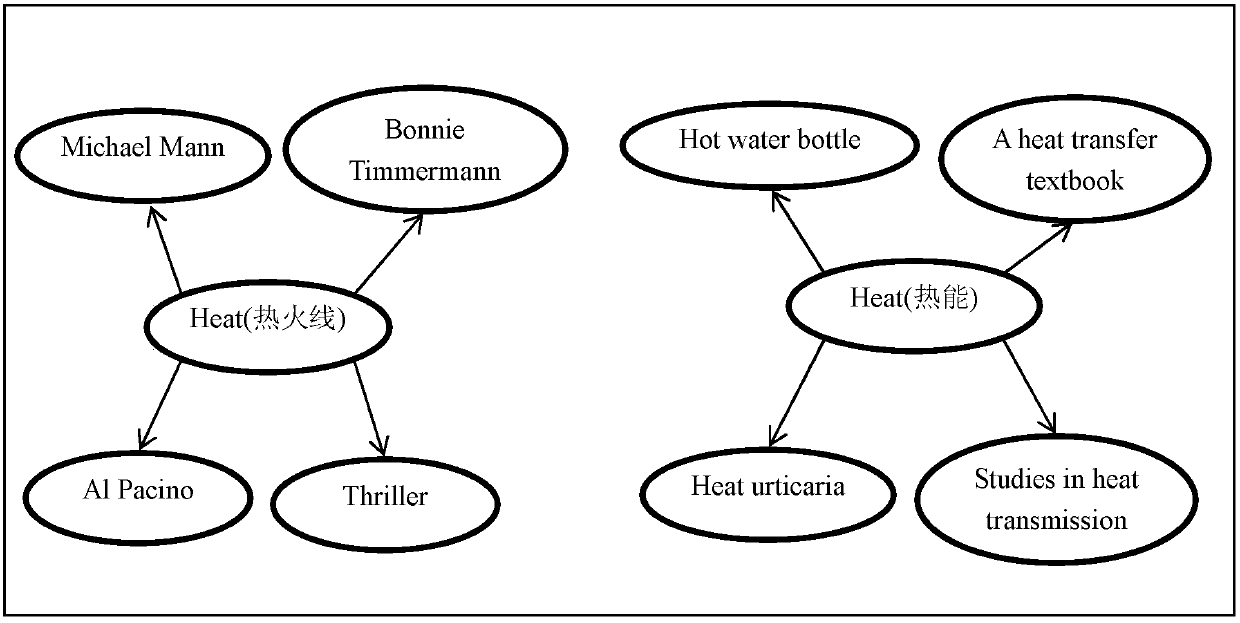
[0038] Specific embodiment two: This embodiment is different from specific embodiment one in that: when the source language corpus is preprocessed, the original corpus will be preprocessed such as word segmentation; although the current word segmentation technology can achieve word segmentation very well, However, since many vocabularies are new words, word segmentation technology is still insufficient; named entity recognition technology is also encountering similar problems; however, for the present invention, since the source language side semantic knowledge base is known, therefore
[0039] Step 1: Use the source-language-side semantic knowledge base to construct a source-language-side entity vocabulary, where the source-language-side entity vocabulary includes the names of all entities in the source-language-side semantic knowledge base (the entity is generally a specific person and one One word in kind);
[0040] Step 12: Add the source language-side entity vocabulary obtaine...
specific Embodiment approach 3
[0041] Specific embodiment three: this embodiment is different from specific embodiment one or two in that: in step two, the source language corpus with the entity marked in step one is used to construct a topic model, and the specific topic distribution of the entity is calculated according to the topic model process:
[0042] Step two: Use the source language corpus with entities obtained in step one to train the topic model to obtain the word-topic distribution:
[0043]
[0044] Where s i Represents the words in the source language corpus where the entity is annotated, i∈{1,2....,V s }, V s Is the size of the vocabulary in the source language corpus where the entity is annotated; z k Is the k-th topic, k∈{1,2,...,K}, K is the total number of topics;
[0045] Step two, use the word-topic distribution obtained in step two to obtain the topic distribution of each entity:
[0046] Other steps and parameters are the same as those in the first or second embodiment.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More