

Canonical-correlation-analysis-based computer data attribute reduction method
A typical correlation, data attribute technology, applied in the field of data processing, can solve the problem of not considering the conditional attribute correlation in the information table
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
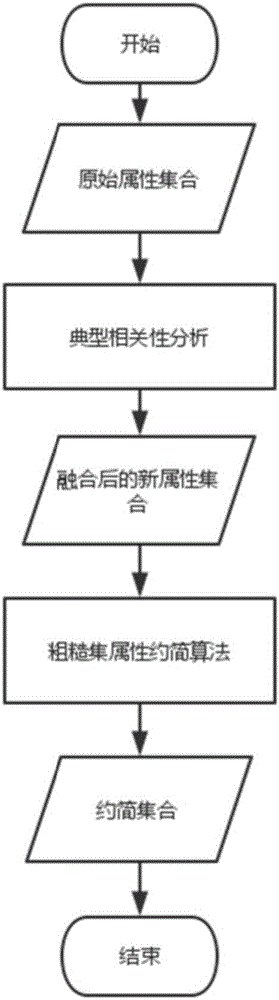
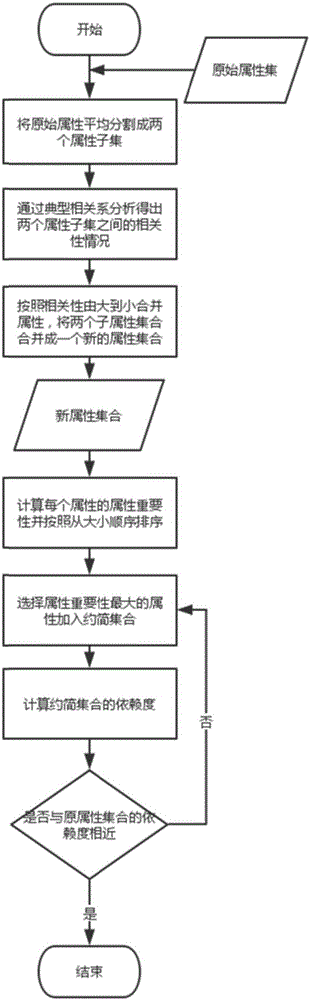
[0069] Each step of the present invention is described below according to an embodiment. The method of the present invention is basically applicable to all data used for classification processing. This embodiment takes common text data as an example. Douban will classify a large number of books in order to recommend books of a certain category to users. If it is almost unrealistic to classify these books manually, it will be of great practical significance to automatically classify books according to their text content. However, the biggest problem with text processing is that the text data contains a large number of words, resulting in a high dimension of the text, and some even reach tens of thousands of dimensions. At the same time, this tens of thousands of dimensional data usually contains a lot of useless data, which not only interferes with the classification accuracy, but is also very time-consuming. Therefore, it is necessary to reduce the attributes of such data, ...
Embodiment 2
[0110] The second dataset comes from two medical institutions. The data set contains diagnostic information of normal people and patients, and the purpose is to distinguish between normal person diagnostic data and patient diagnostic data based on these data. All the data are mass spectrometry data extracted by SELDI technology, and then the mass spectrometry data is processed to obtain 10,000-dimensional features. However, these 10,000-dimensional features contain a lot of redundant information. If they are directly distinguished, the classification effect will not be very good, so it is necessary to reduce the dimensionality first.
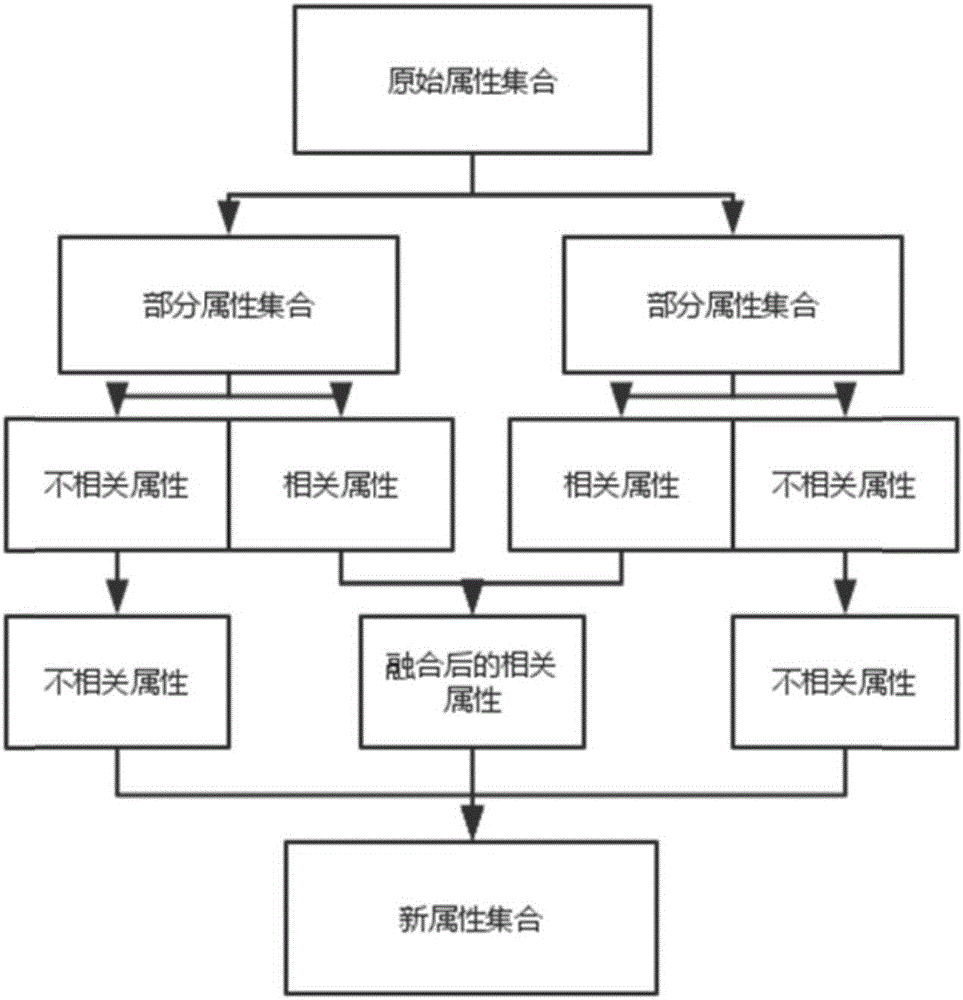
[0111] For the typical correlation analysis stage of step (1), the data attribute set is also divided into two sub-sets, and the attribute dimension of each set is 5000. Afterwards, attribute correlation analysis is performed on it. Because the attribute dimension is large, the fusion granularity is set slightly larger here, which is 100, 300, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More