Method for classifying and analyzing massive logs by applying Apache Spark
A log, massive technology, applied in the information field, can solve the problems of poor iterative data processing performance, lack of overall logic, and difficult to use, and achieve the effect of improving log parsing speed, parsing accuracy, and usage efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0020] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
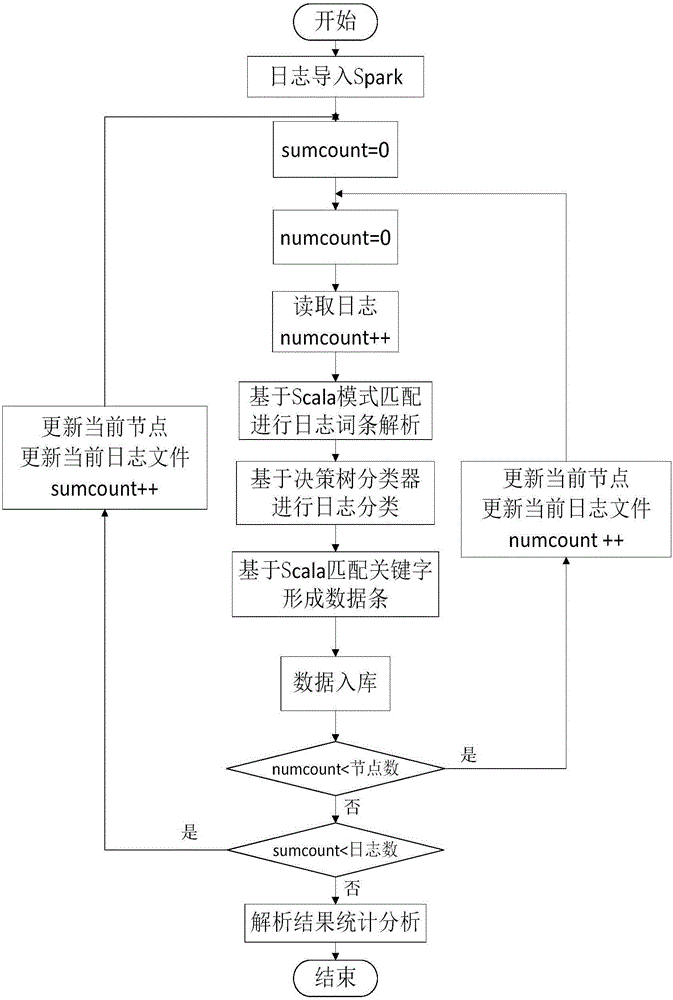
[0021] figure 1 A flow chart of a method for classifying and parsing massive logs using Apache Spark of the present invention is shown. First, obtain important operating parameters, including parameters such as running time, number of running distributed nodes, and total log running volume. value. Secondly, import the log files into the Spark environment, select the node number file, read one of the log files into the decision tree classifier, and analyze the file name of the log file and the description field of the log file based on the pattern matching command of Scala. Take the key fields, including host na...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com