

Spark memory computing big data platform-based CLR multi-label data classification method
A big data platform, memory computing technology, applied in computing, data mining, electrical digital data processing and other directions, can solve the problem of not being able to process data quickly, not being able to use a large amount of historical data in a timely and effective manner, and model taking a lot of time, etc. problems, to achieve the effect of reducing the risk of downtime, reducing storage space, and reducing time efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
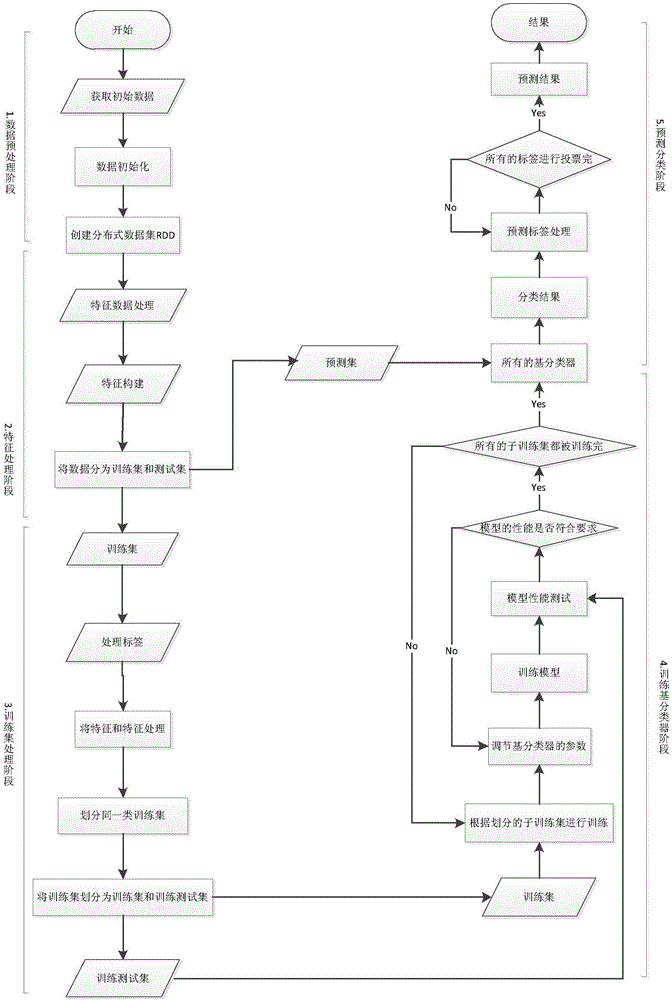
[0032] figure 1 Adopt Spark to carry out CLR multi-label learning algorithm flowchart for the present invention, comprise the following steps;
[0033] (1) Data preprocessing stage
[0034] Including steps: data acquisition, transformation of non-nominal data, missing value compensation and normalization of data.
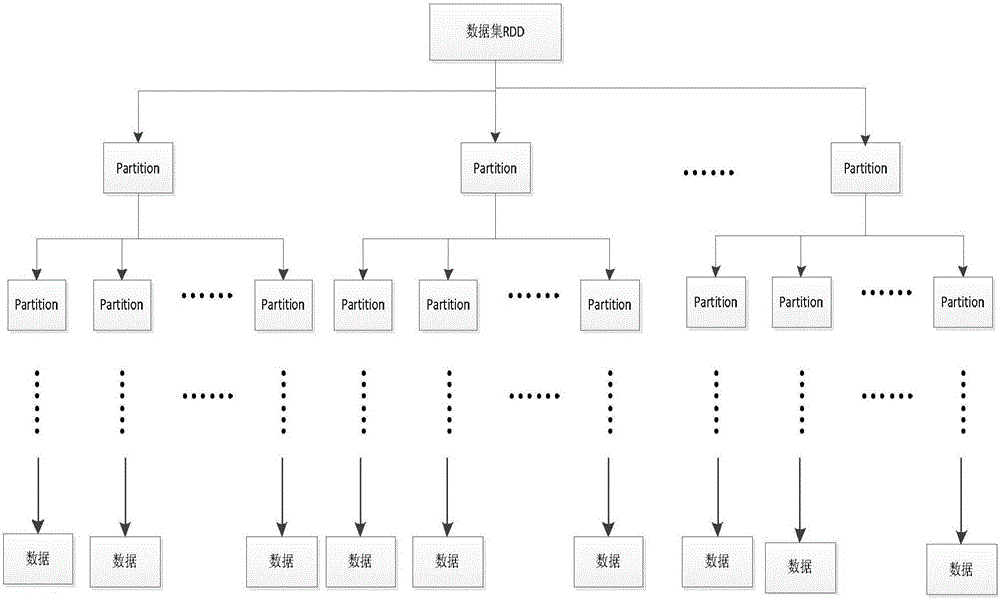
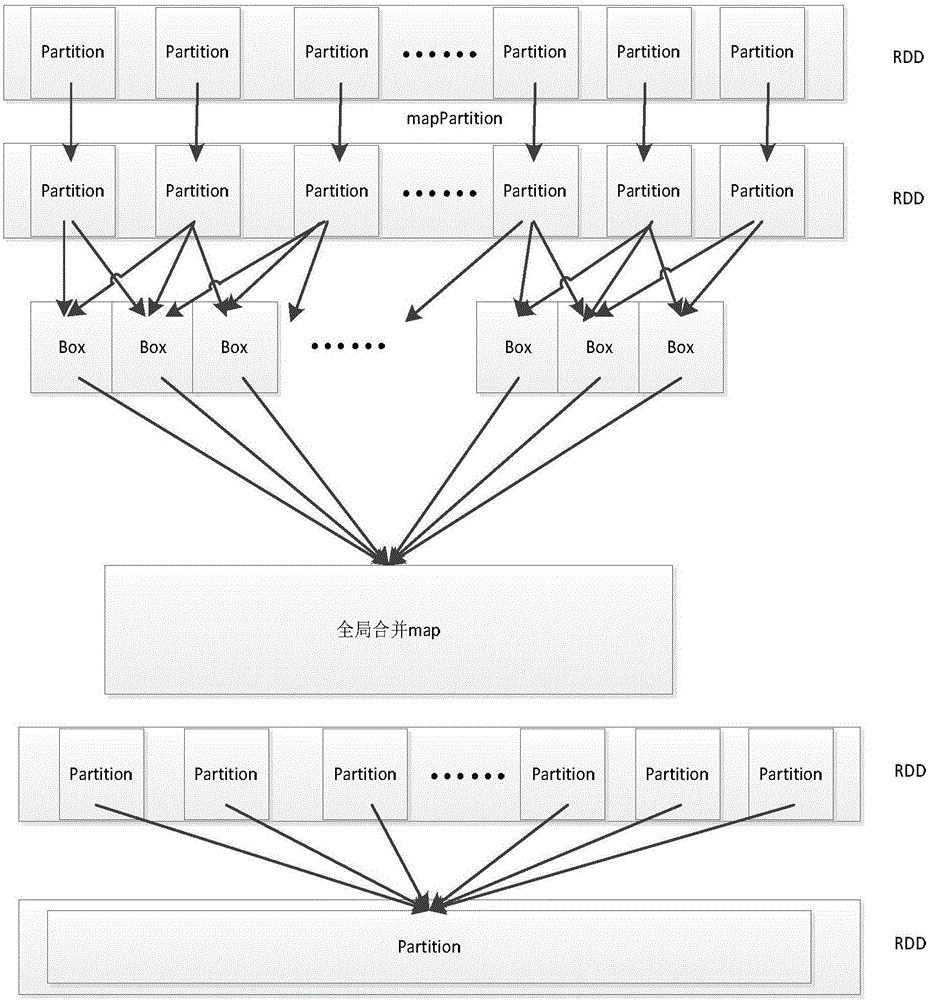
[0035] Obtaining data specifically includes: creating a SparkContext object (SparkContext is the external interface of Spark, which is responsible for providing various functions of Spark to the call. It functions as a container), SparkContext is the entrance of Spark, and is responsible for connecting to the Spark cluster; then use Spark's textFile(URL) (a function that serializes RDD to a distributed file system) reads the dataset, where the URL can be the address of a local data file (for example: C: / dataset.txt) or hdfs (Hadoop Distributed File System: Hadoop Distributed File System) above the address (for example: hdfs: / / n1:8090 / user / hdfs / dataset.txt), conver...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More