

Data processing method and device based on Spark
A data processing and data type technology, applied in the computer field, can solve the problem of high technical requirements of the queryer, and achieve the effect of simple and easy to use
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
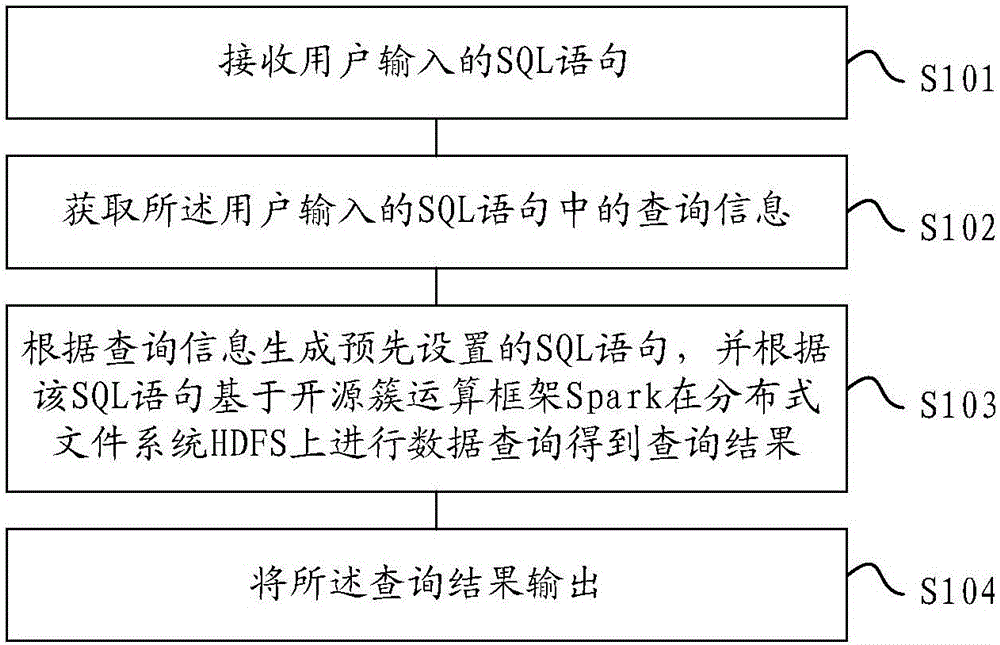
[0070] Example 1, query the alarm data of Haier's drum washing machine on October 14, 2016, and save it in a csv file: the program of the embodiment of the present invention-q "select * from alarm data"-t20161014-p' drum washing machine number' -o / data / query result.csv;
[0071] That is, the data type is alarm data, the time is 20161014, and the device type is the drum washing machine serial number.
example 2
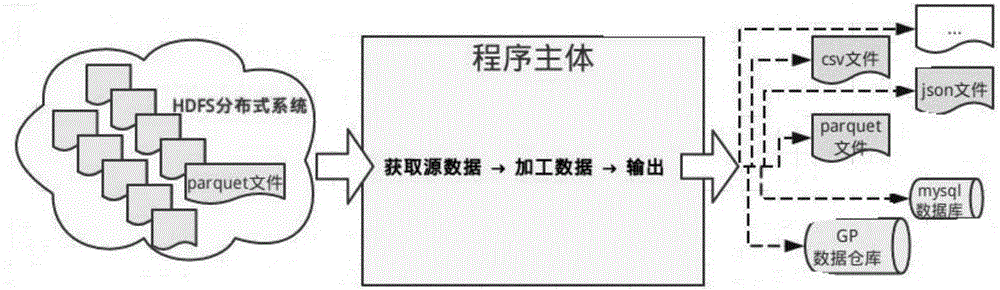
[0072] Example 2, the small files of a large amount of Parquet formats under the / sample / directory on the HDFS are merged into 7 large files: the program-q of the embodiment of the present invention "select*from / sample / *.parquet"-o / data / Merge file .Parquet7.
[0073] Device embodiment
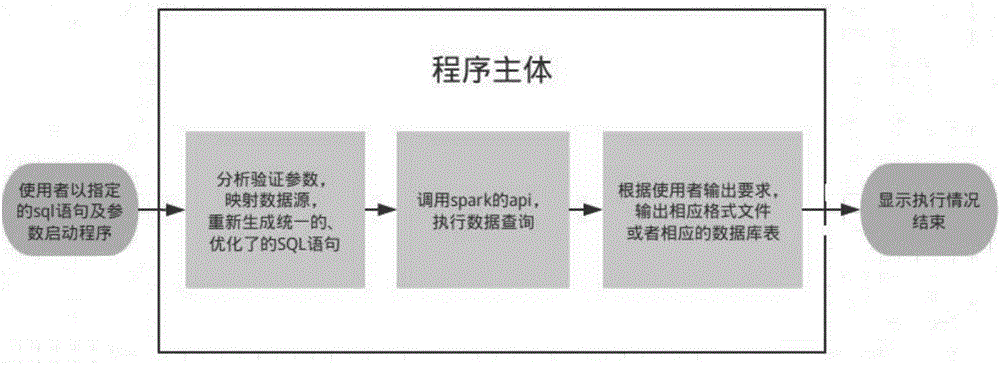
[0074] The embodiment of the present invention provides a Spark-based data processing device, see Figure 4 , the device includes: a receiving unit, used to receive the SQL statement input by the user; an acquisition unit, used to acquire the query information in the SQL statement input by the user; The content of the "-t" field is recognized as the data type, the content after the "-t" field is recognized as the time, and the content after the "-p" field is recognized as the device type, and the pre-set SQL statement is generated according to the data type, time and device type, and According to the SQL statement, data query is performed on the distributed file system HDFS based on the ope...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More