Sorting algorithms for high dimensional data
A classification algorithm and high-dimensional data technology, applied in the field of data processing, can solve problems such as unbalanced classification accuracy, inability to obtain good classification results, and inability to effectively deal with high-dimensional data subspace selection problems.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0081] In order to make the technical means, creative features, goals and effects achieved by the present invention easy to understand, the present invention will be further elaborated below in conjunction with illustrations and specific embodiments.
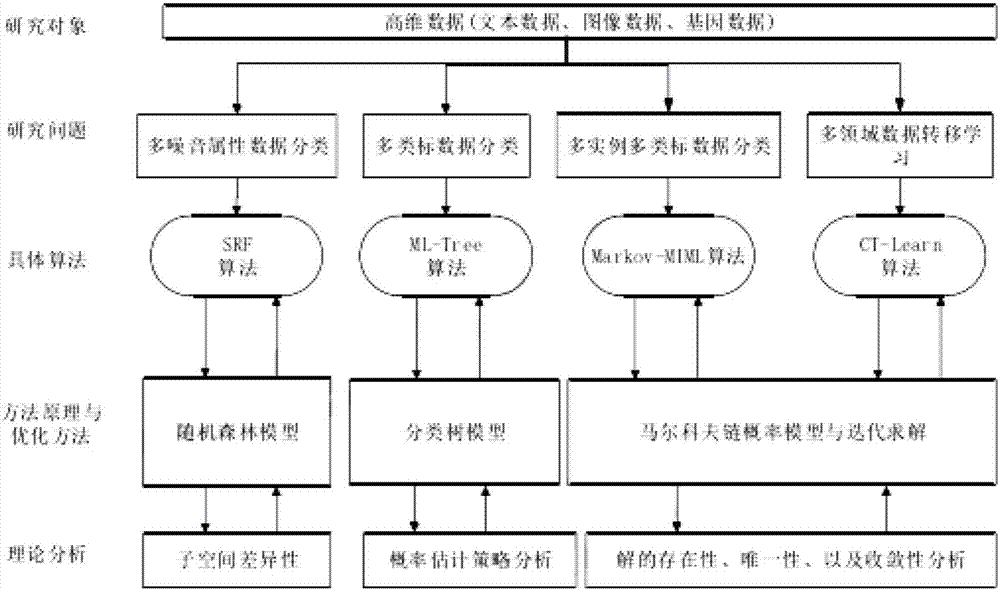
[0082] see figure 1 , the present invention provides a classification algorithm for high-dimensional data: including random forest algorithm, ForesTexter algorithm, GW-SRF algorithm;
[0083] Random forest is a decision tree ensemble learning model. The algorithm flow of random forest can be described as follows:
[0084] 1). First, use the Bagging sampling method to sample the training data set X with replacement (Sample with replacement), and obtain K data subsets {X1, X2,...,XK};
[0085] 2). For each training data subset Xk, use the CART [91] method to construct a decision tree. For each node of the decision tree, randomly select p attributes (p≤N) from the attribute space S as a set of attributes subset (attribute subspac...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More