

Method for automatically identifying document research on the basis of text
An automatic identification and document technology, applied in natural language data processing, special data processing applications, instruments, etc., can solve the problems of high recall rate, poor flexibility, low accuracy rate, etc., to improve the improvement effect and improve the indexing ability. , the effect of the simple method
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
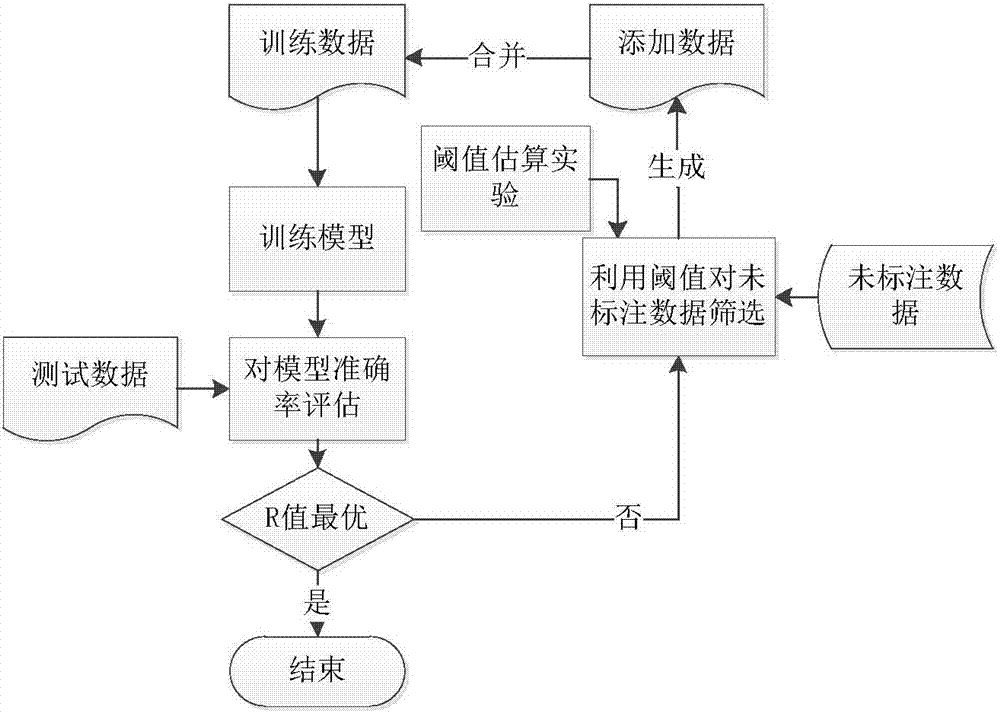
[0028] A text-based method for automatically identifying literature research objects, including firstly modeling a small amount of labeled data based on the CRF model, then predicting unlabeled data, and then selecting as few as possible parts of the data from most labeled sets for manual Annotate, then add the annotated results to the original corpus to re-model, and iterate the process appropriately to obtain the final module, and this model can be used to extract the research objects of scientific and technological literature. The specific steps are as follows:
[0029] Step 1: Obtain the title of scientific and technological literature and make initial annotation
[0030] Obtain a large collection of titles S of scientific and technological literature, and extract a small number of titles of scientific and technological literature S1(S 1 The total amount is greater than 2000) and manually mark these titles, mark the research objects mentioned in the corresponding titles, m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More