

C-DBSCAN-K clustering algorithm under Hadoop platform
A C-DBSCAN-K, clustering algorithm technology, applied in the field of C-DBSCAN-K clustering algorithm, can solve problems such as low clustering efficiency, and achieve the effect of speeding up the operation speed and improving the execution efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0041] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
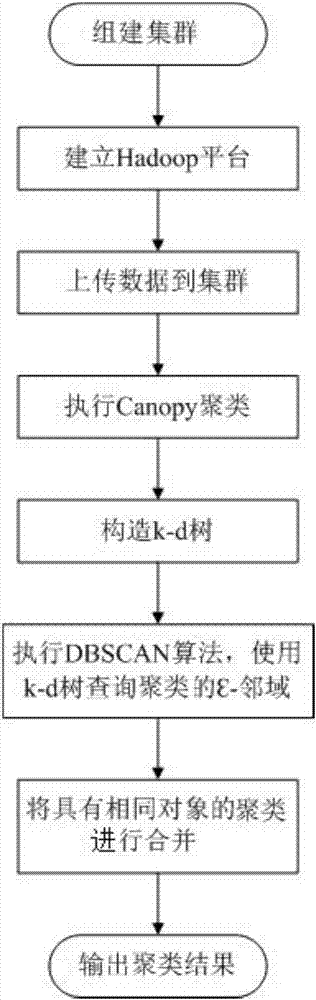
[0042] Such as figure 1 As shown, the C-DBSCAN-K clustering algorithm under the Hadoop platform includes the following steps:
[0043] Step 1, connect multiple computers to the same local area network, and each computer acts as a node to establish a cluster that can communicate with each other;
[0044] Step 2, build the Hadoop platform for the cluster;
[0045] Step 2 is specifically: firstly install the redhat6.2 operating system for each node in the cluster; then install the Hadoop2.2.0 file for each node in the cluster, and install the jdk1.8.0_65 file for each node in the cluster; configure each node in the cluster The .bashrc file of the redhat6.2 system on each node makes the redhat6.2 system associate the Hadoop2.2.0 file on the node with the jdk1.8.0_65 file on the node; configure hadoop in the Hadoop2.2.0 file on each node -env.s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More