

Text classification and device
A text classification and text technology, applied in the computer field, can solve the problems of low accuracy and coverage, long construction time, and low construction efficiency, and achieve the effects of high accuracy, simple operation, and improved coverage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


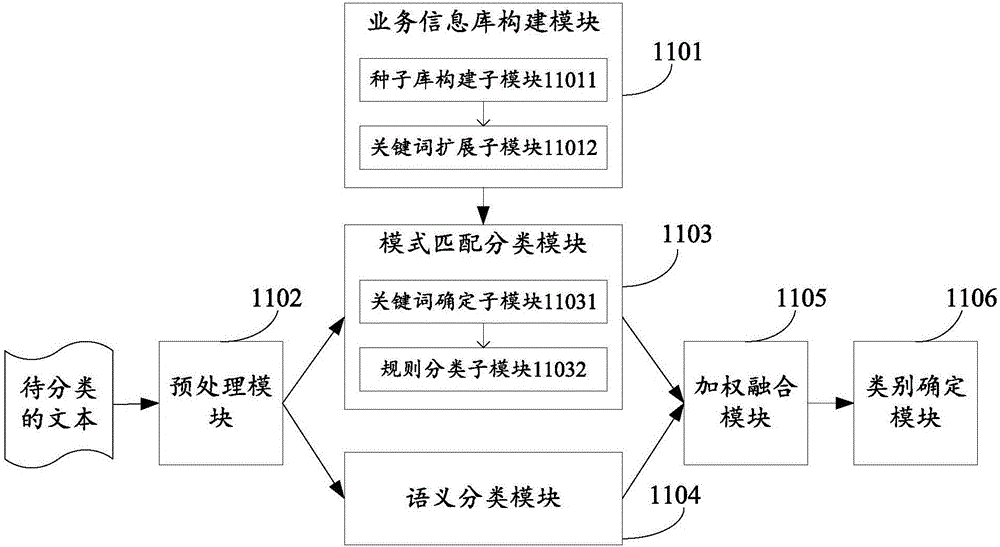
Examples
Embodiment Construction
[0057] In order to make the object, technical solution and advantages of the present invention clearer, the implementation manner of the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0058] Before explaining and describing the embodiments of the present invention in detail, the application scenarios involved in the embodiments of the present invention will be described first.
[0059] The customer service platform is often the most important service window for telecom operators or Internet operators, such as China Mobile 10086 platform, Taobao customer service platform, etc. Taking the mobile 10086 platform as an example, the average daily customer service calls in the first half of 2015 were about 5.5 million. Millions of pieces of customer service data are stored in the mobile 10086 platform every day. Conversation log. Since the customer service data is often stored in the form of recording, in order to facilit...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More