Method for constructing decision tree based on differential privacy protection
A differential privacy and decision tree technology, applied in digital data protection, instrumentation, electrical digital data processing, etc., can solve the problems of inefficient selection methods and depletion of privacy budget, so as to protect privacy, improve accuracy, and reduce rapid consumption Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

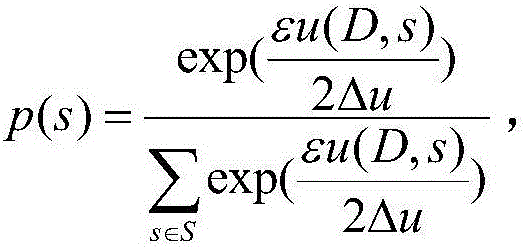
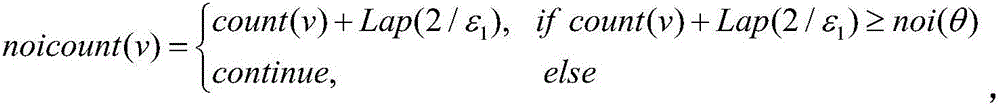
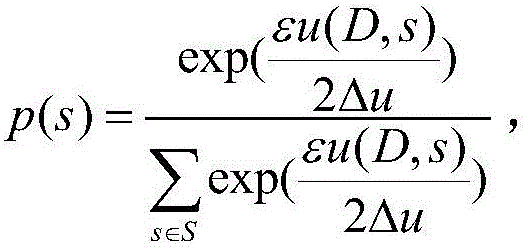
Examples
Embodiment Construction
[0019] The present invention will be described in detail below in conjunction with the examples.
[0020] The present invention provides a method based on differential privacy protection decision tree, which aims at the differential privacy protection of the classic greedy decision tree C4. A protection mechanism alters this answer in a way that preserves the privacy of everyone in the dataset. The present invention comprises the following steps:
[0021] 1) Use Bernoulli (Bernoulli) random sampling principle to sample the original data set with sampling probability p to obtain a data set sample, and the obtained data set satisfies ln(1+p(e ε -1))- Differential privacy:
[0022] Perform Bernoulli random sampling on the original data set with the assumed sampling probability p, put the selected samples into the spatial samples, otherwise discard them, and calculate the privacy budget ε required to build the entire decision tree under the sampling probability p p . Among the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com