

Text classification based on tfidf algorithm and related word weight correction
A technology for text classification and related words, applied in the computer field, can solve the problems of inability to complete the adjustment of weights, the accuracy of text classification is not very high, and cannot effectively reflect the importance of words and the location distribution of characteristic words. and processing cycle is short, efficient and accurate extraction, extraction comprehensive and accurate effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
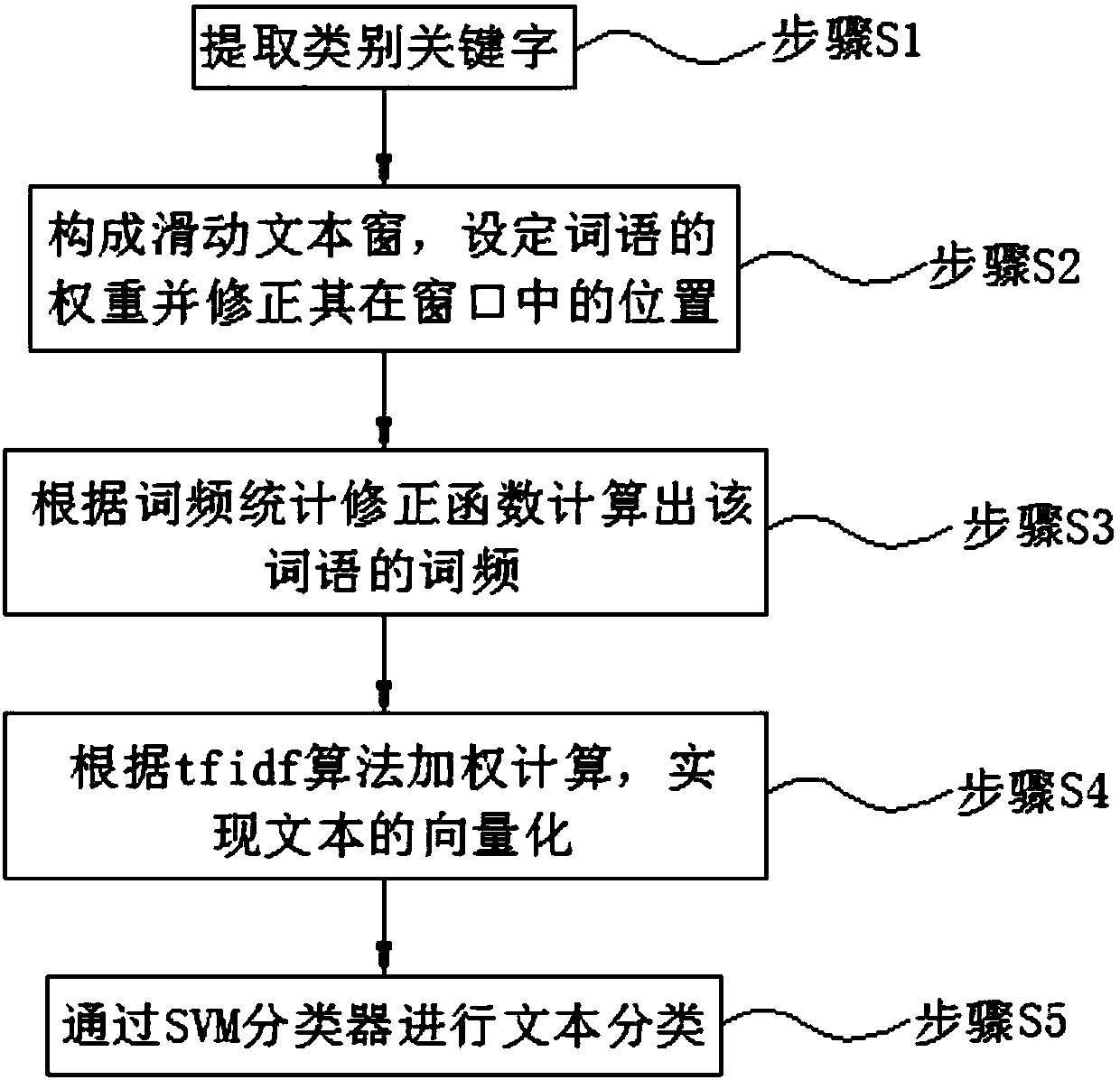
[0046] like figure 1 As shown, a text classification method based on tfidf algorithm and related word weight correction, including the following steps:
[0047] S1: Extract category keywords from part of the training data or according to the keywords provided by the user;
[0048] S2: Form the word segmentation results of the text into a sliding text window, set the weight of each word, and correct its position in the sliding text window;
[0049] S3: According to the weight of the word and its position in the sliding text window, the word frequency of the word is calculated according to the word frequency statistical correction function;
[0050] S4: according to the TFIDF algorithm, the words of the text are respectively weighted and calculated to realize the vectorization of the words of the text;
[0051] S5: After the vectorization of the text is realized, the text is classified through the svm classifier.
[0052] Compared with the traditional tfidf algorithm, the acc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More