

Text similarity computing method and device
A technology of text similarity and calculation method, which is applied in the field of text similarity calculation method and device, can solve the problems of dependence on training samples, impractical large text or big data environment, low calculation efficiency, etc., and achieve the effect of improving calculation efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
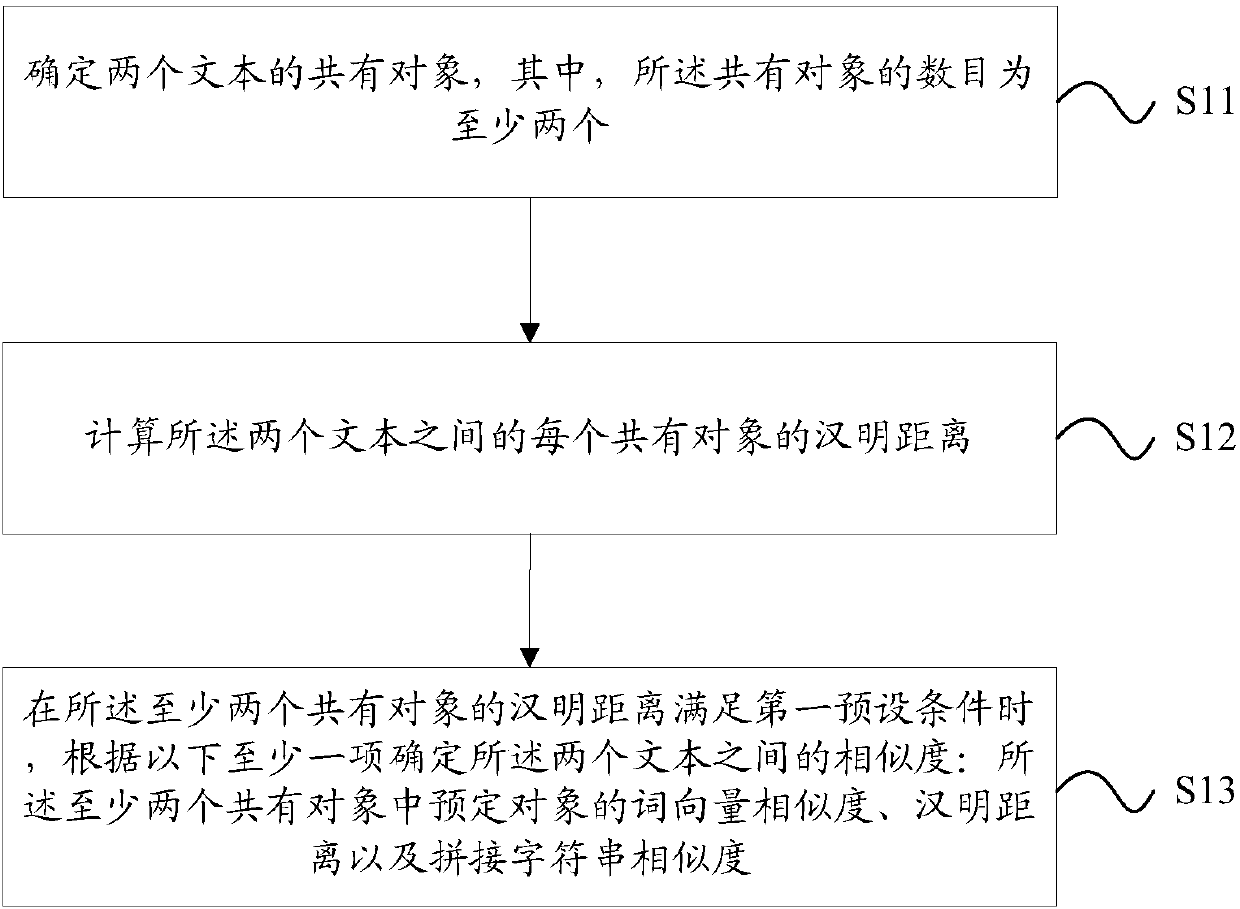
[0062] An embodiment of the present application provides a text similarity calculation method for calculating the similarity between two texts. The text described in this embodiment may include: public opinion texts such as news, microblogs, and forum articles. In this embodiment, the two texts for similarity calculation can be the same type of public opinion texts, for example, it can be two news texts, or two microblogs, or two forum articles; or, the similarity calculation The two texts can also be different types of public opinion texts, for example, it can be a news text and a microblog, or a microblog and a forum article, or a news text and a forum article. However, the present application is not limited to this.
[0063] In this embodiment, data of at least two objects can be extracted from each text. Wherein, the data of the object includes, for example: hash value and / or word vector data. Taking the SimHash algorithm to extract the hash value and the word2vec model...
example 1
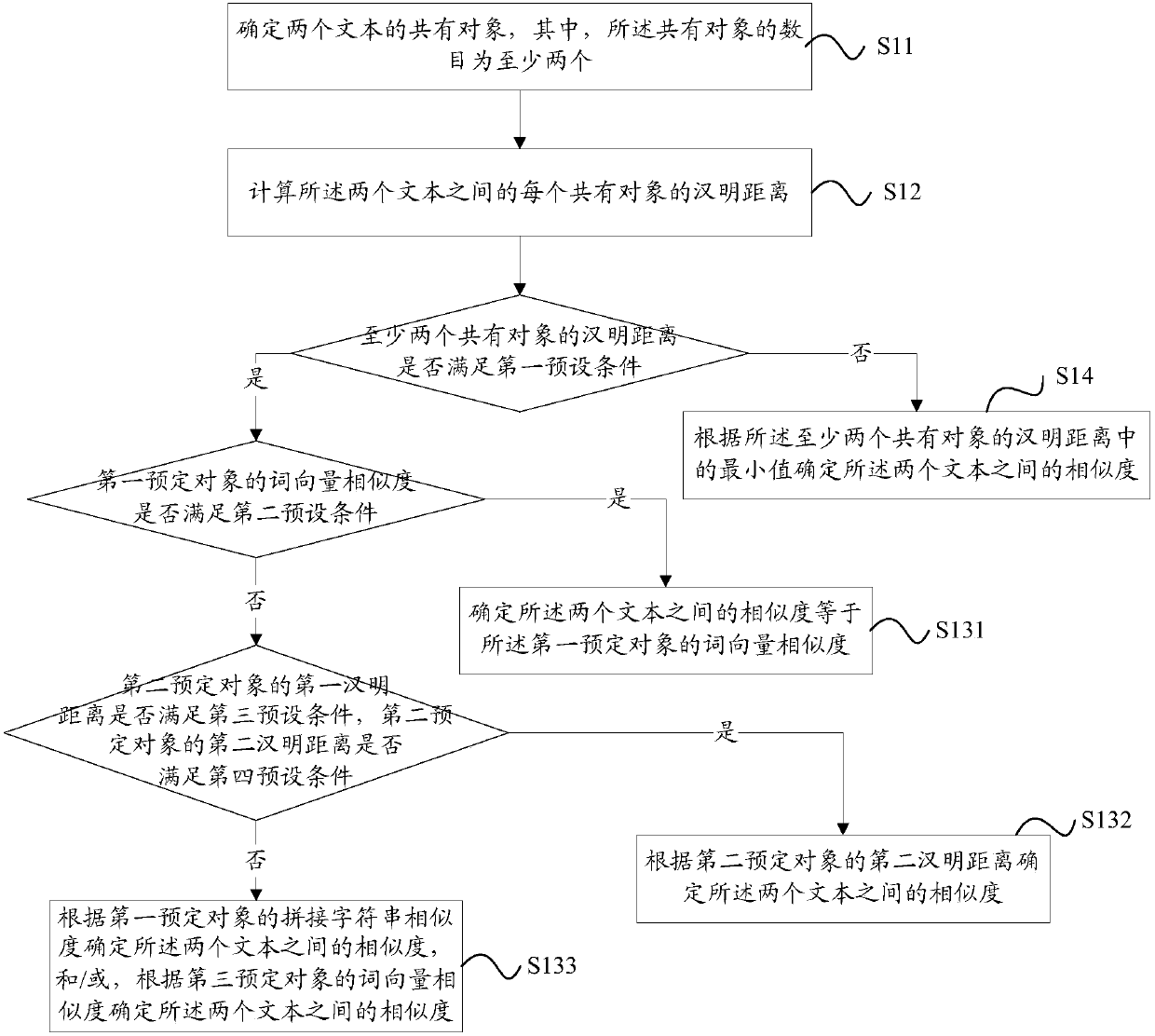
[0129] In this example, the calculation of the similarity between text A and text B is taken as an example for illustration. Among them, the title SimHash value a1, content SimHash value a2, keyword SimHash value a3, core sentence SimHash values a4, a5, a6 (here, take three core sentences as an example), three core sentences are extracted from text A. The total SimHash value a7 of the sentence, the VSM of the title and the VSM of the keyword; from the text B, the SimHash value b1 of the title, the SimHash value b2 of the content, the SimHash value b3 of the keyword, and the SimHash values b4, b5, and b6 of the core sentence (in Here, take three core sentences as an example), the total SimHash value b7 of the three core sentences, the VSM of the title and the VSM of the keywords. Here, the common objects between text A and text B are: title, content, keywords and key sentences.
[0130] Such as Figure 6 As shown, the similarity calculation process between text A and text...
example 2
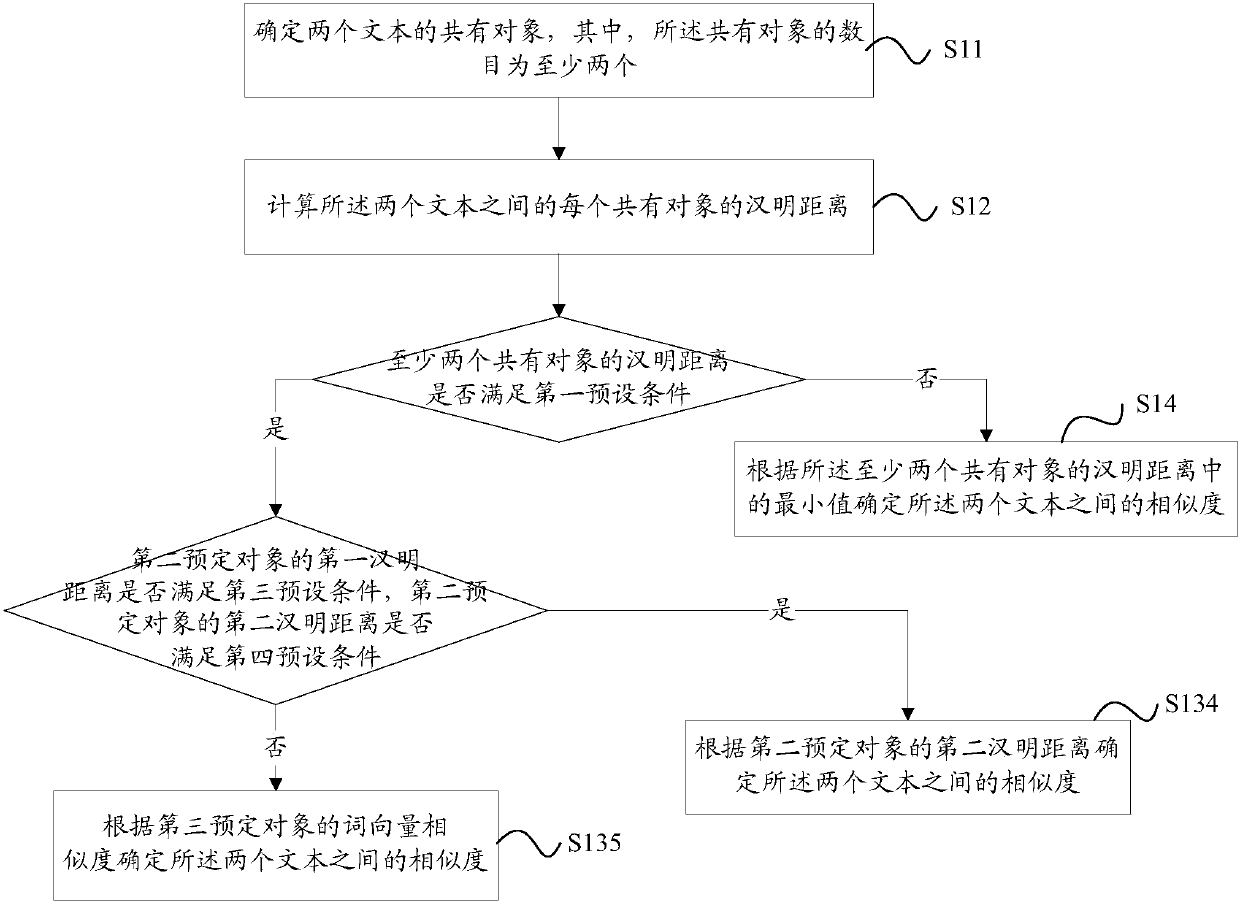
[0181] In this example, the calculation of the similarity between text A and text B is taken as an example for illustration. Among them, the title SimHash value a1, the content SimHash value a2, the SimHash values a4, a5, and a6 of the core sentence are extracted from the text A (here, take three core sentences as an example), and the total SimHash value a7 of the three core sentences , and the VSM of the title; from the text B, extract the SimHash value b1 of the title, the SimHash value b2 of the content, the SimHash values b4, b5, and b6 of the core sentence (here, take three core sentences as an example), the values of the three core sentences The total SimHash value b7, and the VSM of the title. Here, the common objects between text A and text B are: title, content, and core sentences.
[0182] Such as Figure 9 As shown, the similarity calculation process between text A and text B includes the following steps:
[0183] Step 201: respectively calculate the conten...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More