

Extension method and device for distributed database
An expansion method and expansion device technology, applied in the field of distributed database expansion methods and devices, can solve the problems of increasing compatibility, difficult maintenance and adjustment, and suspension, so as to increase the data migration process, reduce the data migration process, Accelerate the effect of data migration
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0078] In order to understand the characteristics and technical contents of the embodiments of the present invention in more detail, the implementation of the embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. The attached drawings are only for reference and description, and are not intended to limit the embodiments of the present invention.
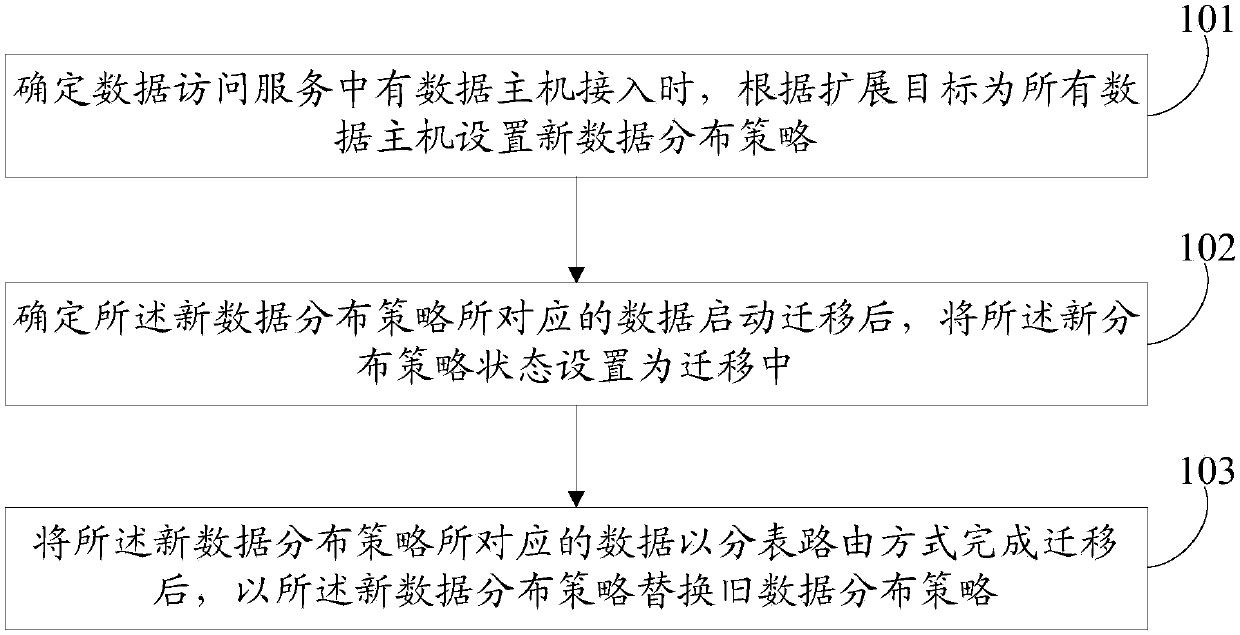
[0079] figure 1 It is a flow chart of the method for extending the distributed database of the embodiment of the present invention, such as figure 1 As shown, the method for extending the distributed database in the embodiment of the present invention includes the following processing steps:
[0080] Step 101, when it is determined that there are data hosts in the data access service, set a new data distribution policy for all data hosts according to the expansion target.
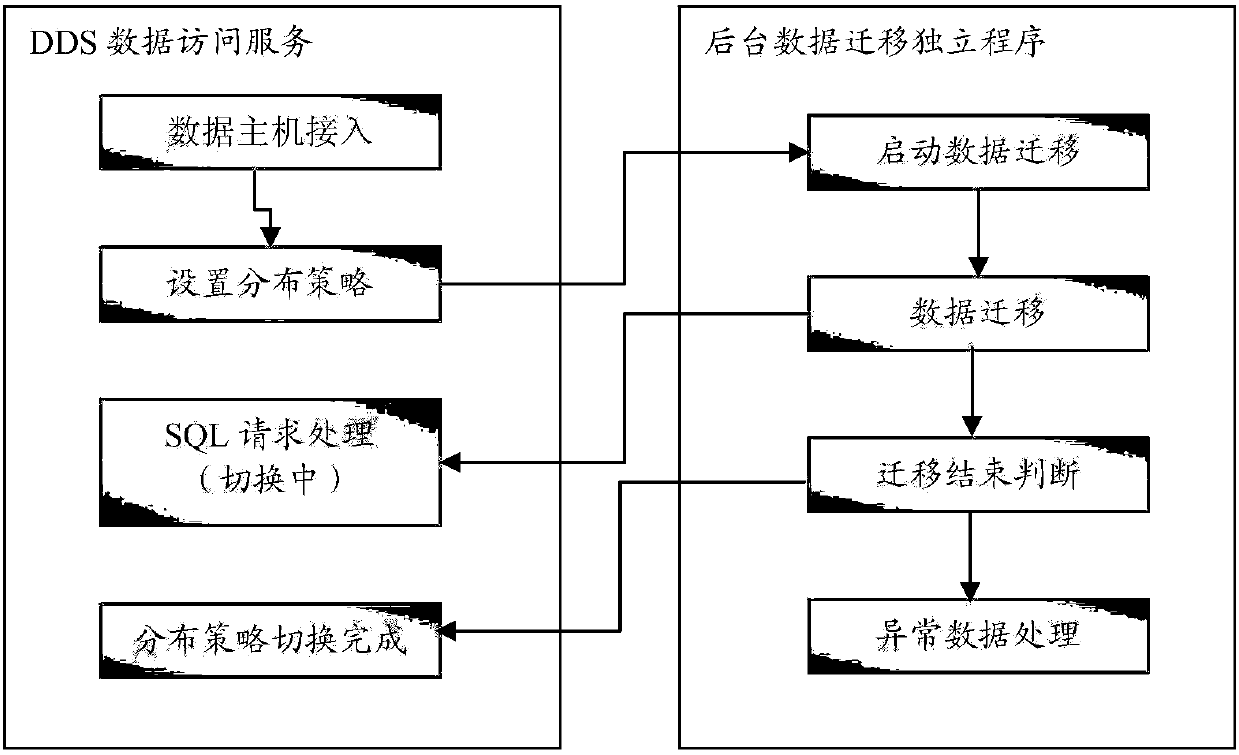
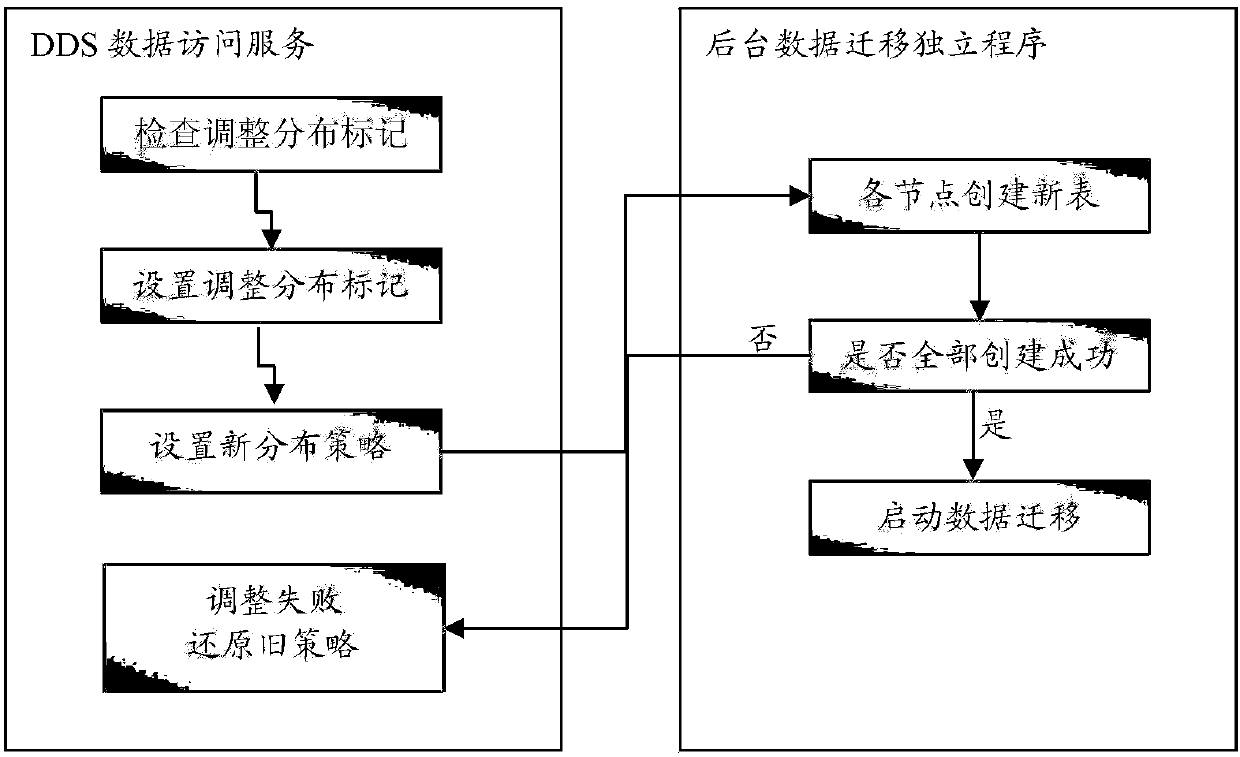
[0081] In the embodiment of the present invention, when a new data host accesses, the current data...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More