

Method for extracting webpage text based on label path and text punctuation ratio feature fusion
A webpage text extraction and label path technology, applied in the field of webpage text extraction based on the fusion of label path and text punctuation ratio features, can solve the problems of different establishment, number of features, complex content, no longer applicable templates, etc., and achieve simple calculation methods , Extract the content of the text comprehensively and improve the effect of accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

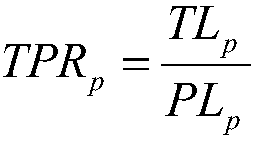
Examples
Embodiment Construction
[0046] The present invention will be further described below in conjunction with specific examples.
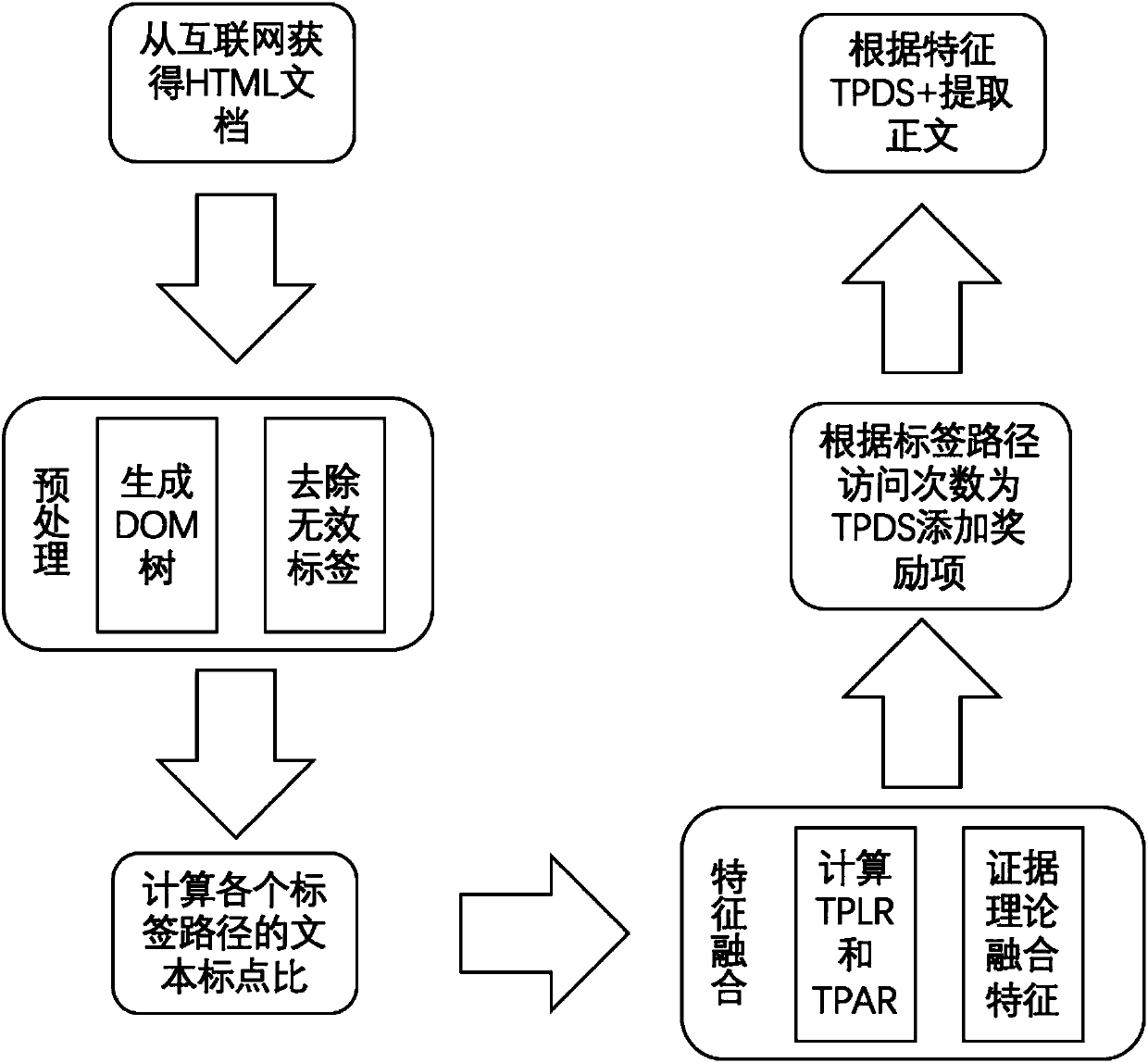
[0047] Such as figure 1 As shown, the webpage text extraction method based on label path and text punctuation ratio feature fusion provided by the present embodiment comprises the following steps:
[0048] 1) Establish a DOM tree according to the HTML document and perform preprocessing;
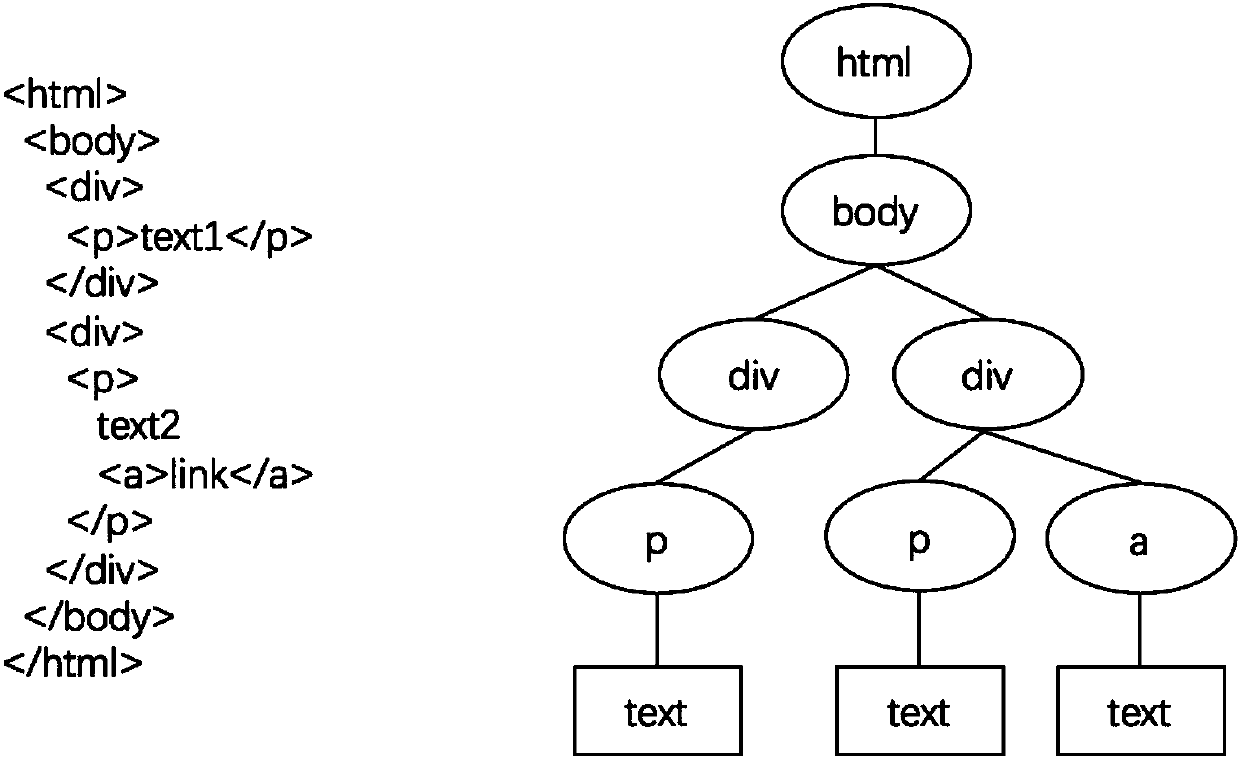
[0049] In this step, the syntax format of the HTML document of the web page may not be standardized. You need to use the html tidy tool to standardize the syntax of the document, and then use existing tools such as Jsoup to directly convert the input HTML document into a DOM tree. DOM tree and html The corresponding relationship is as figure 2 shown. After converting to a DOM tree, delete tags that are known to be impossible to be text content, and tags that are invisible during web browsing can be deleted directly, such as script tags and style tags in css. Among them, the script tag co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More