

Method for processing two-category unbalance medical data
A medical data and binary classification technology, applied in the field of data classification, can solve problems such as loss of useful information, achieve feature selection of accurate attributes, solve data imbalance problems, and have broad application prospects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
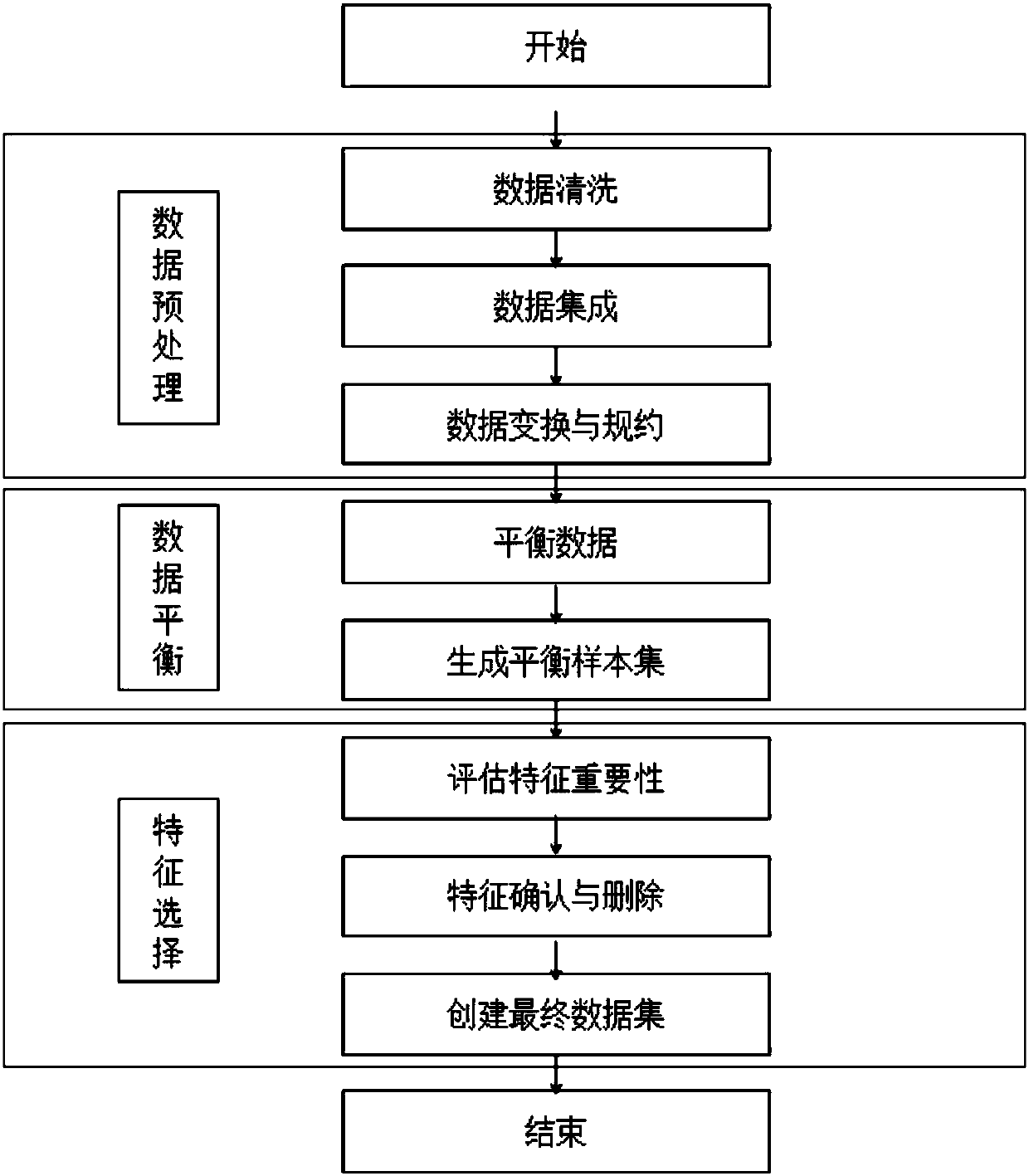
[0030] Embodiment 1: A method for processing two-category unbalanced medical data, the specific steps are as follows: first, preprocess the data, delete the original data set that has nothing to do with the subject of the classification, duplicate data, then smooth the noise data, and process outliers and missing value; secondly, integrate the data from different data sources, solve the problem of entity recognition and attribute redundancy, and standardize the data; and then use the ROSE method to unbalance the data, thus solving the imbalance problem of the two-category medical data .
[0031] The specific operation steps are as follows:
[0032] (1) Data cleaning: Preprocess the medical raw data sets from multiple data sources that need to be classified, delete the duplicate data irrelevant to the classification theme in the original data set, smooth the noise data, and then perform missing value processing. If the missing value of an attribute is greater than 30%, the att...
Embodiment 2
[0040] Embodiment 2: as Figure 1~6 As shown, the data in this embodiment uses UCI machine learning data of 10-year diabetic patient readmission data sets from 130 hospitals in the United States to deal with the imbalance of the original medical data. The specific steps are as follows:
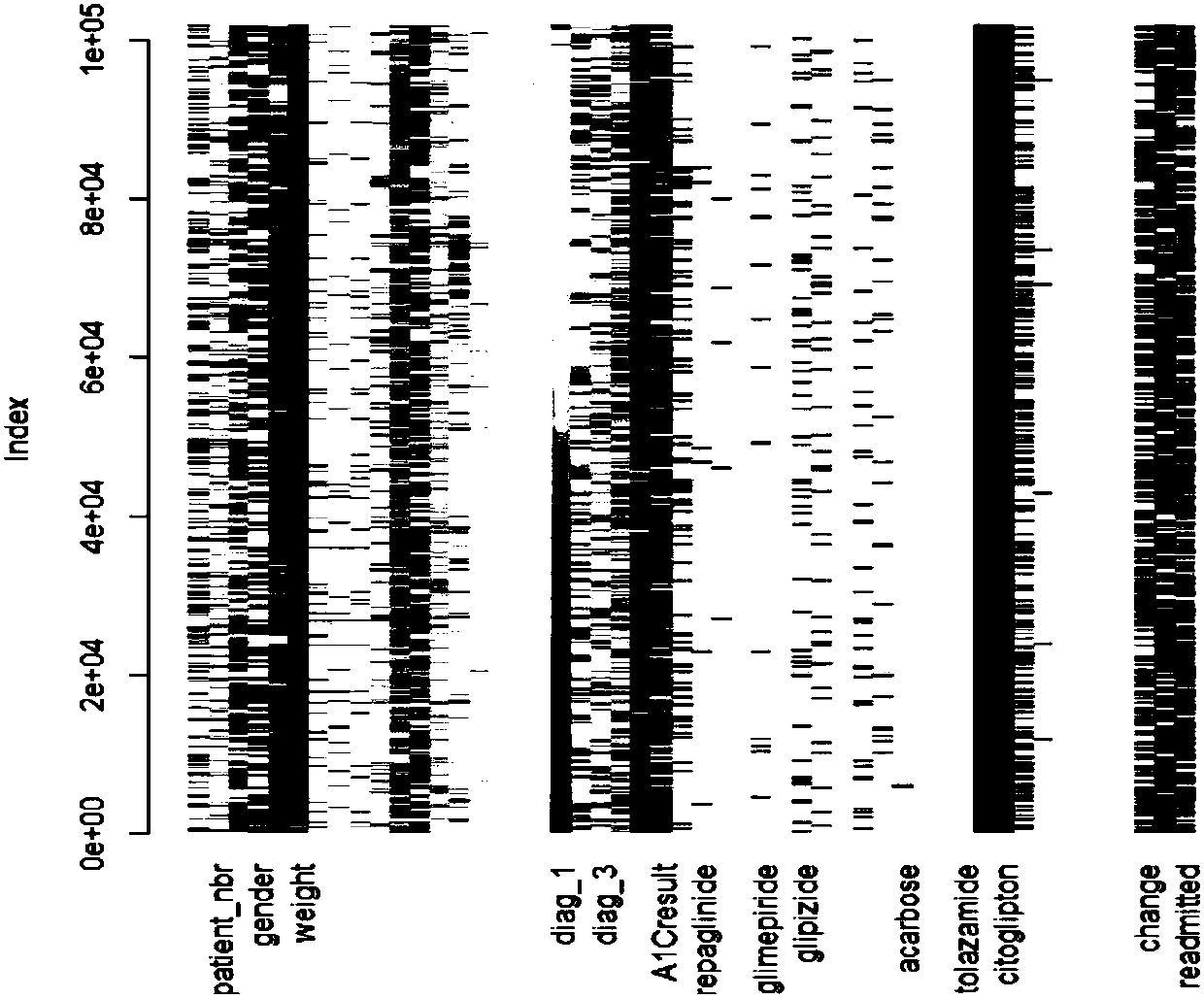
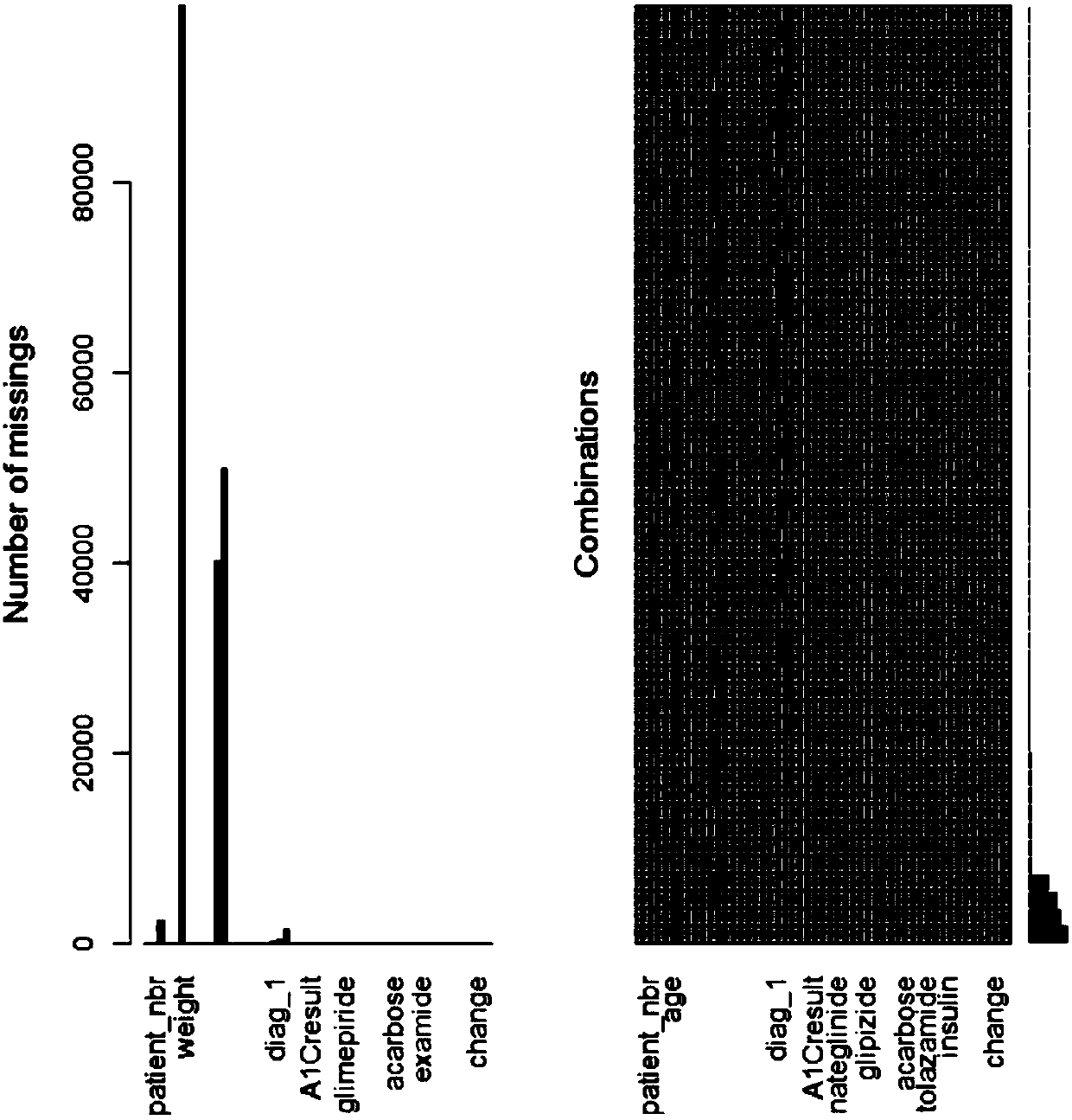
[0041] (1) Data cleaning: Preprocess the 10-year medical raw data sets of 130 hospitals, delete the duplicate data irrelevant to the re-admission of diabetic patients in the original data set, smooth the noise data, and then perform missing value processing. If the missing value of an attribute is greater than 30%, the attribute will be deleted directly. If the missing value of an attribute is less than 30%, the missing value will be supplemented by Lagrangian interpolation method. The processing of outliers is also in accordance with The method of missing values is carried out, and this embodiment shows the matrix diagram of real values and missing values by row, such as figure 2 As s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More